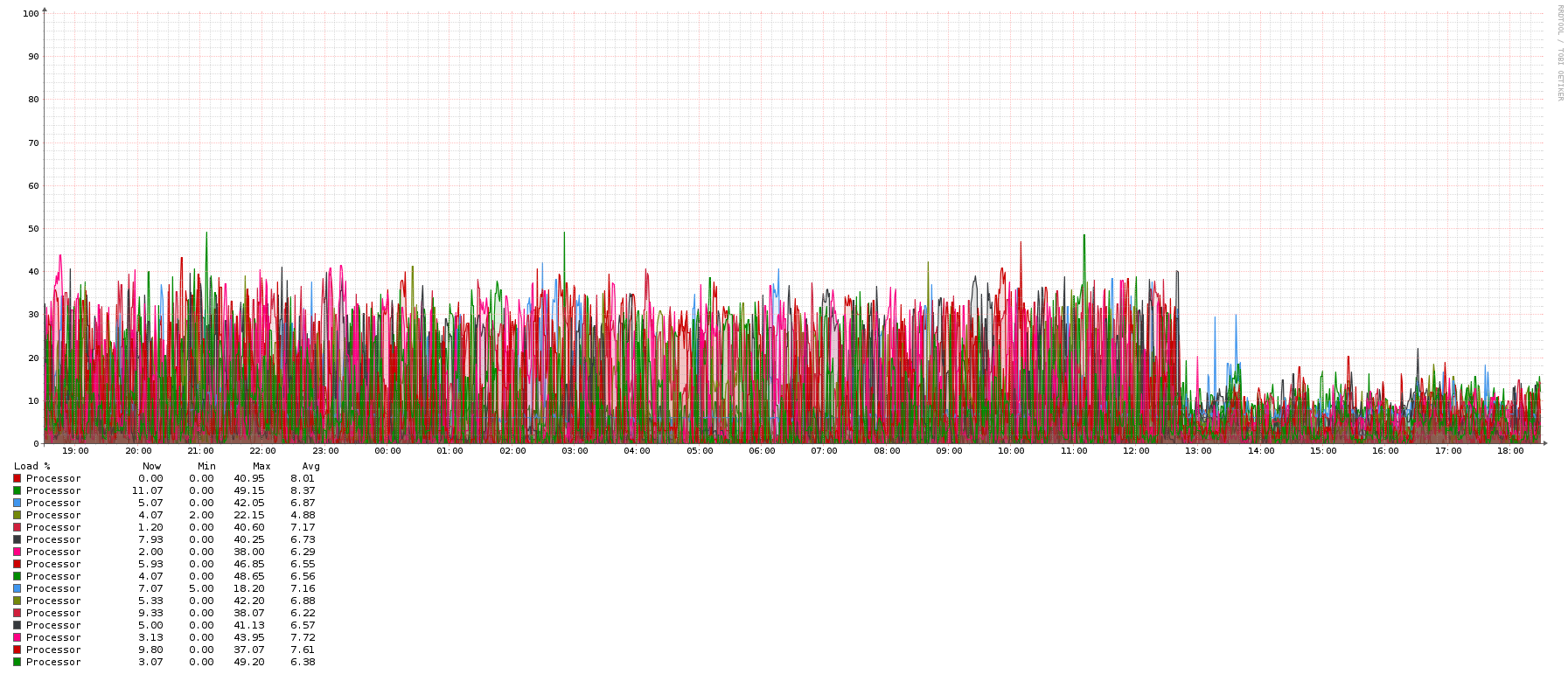
So, i have this mikrotik CCR that serves 1240 Vlans (that are counted and reported as ports)…
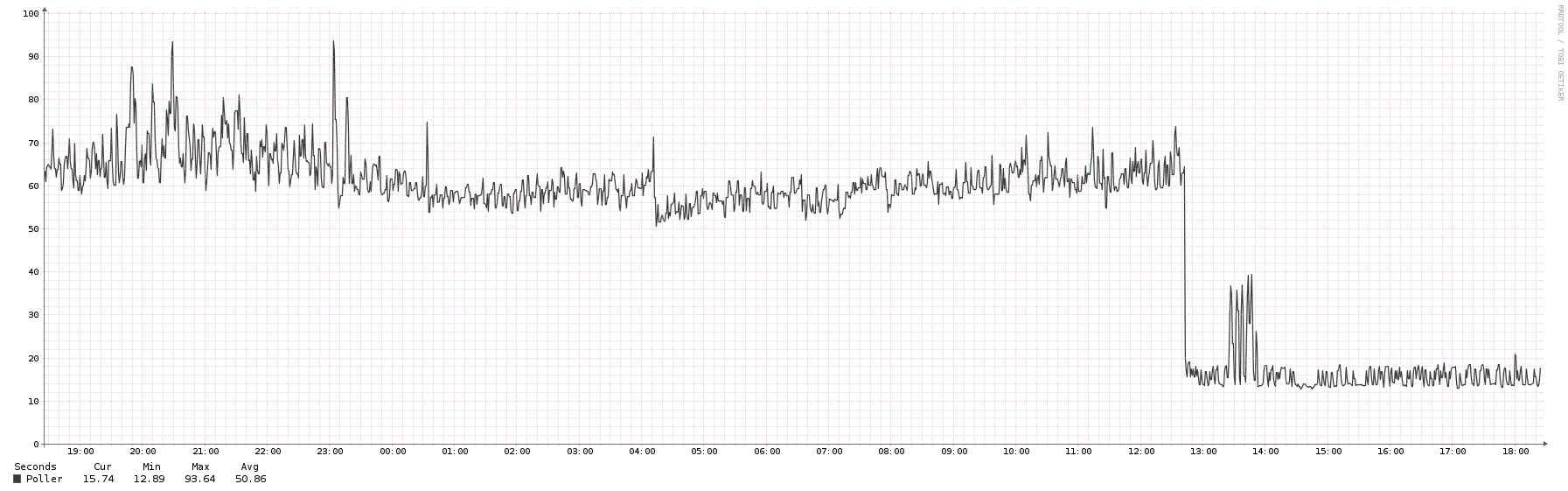
As ports were added, the polling times went from 40 to 73 seconds, and as i have 1 minute polling, i went to try some of the recommended optimizations.
of note: this LibreNMS installation has -the one- device, this mikrotik CCR, that is plugged directly in the librenms box via ethernet. That’s the only thing it has to monitor (and 127.0.0.1, but it polls in 1/2 a second…)
i tried the max_repeaters command line, and a value of 40 finishes in about 7-8 seconds
(10 takes 40 seconds, 25 finishes in 17 seconds.)
i then tried setting Max_Repeaters to 40 both via web (device-specific), and in config.php (globally), but the actual polling times did not change at all.
per-port-polling was enabled, so i then ran the optimization script with “-e 50” argument, and the script found that full-polling finishes in 13 seconds, vs 84 for per-port, so it automagically un-set that parameter, but still, no change at-all in the polling-time graph.
I tried rebooting the centos VM between both config changes, gave them a few hours to gather some poll-cycles, but no dice.
i’m lost as to why whatever i do to the configs, the polling times stay the same. all help appreciated.