Hi, I’m running into a case. I’m going to monitor about 2.000 devices. Right now, I have 2 pollers polling 500 devices. Is it enough by using just 2 pollers to poll 2.000 devices? Or should I add more? Is there any reference for how many devices to poll a poller capable of?
I have been following this topic but still have no clue what should i do. Please help. Thank You
I’ve found it depends on several factors. If you’re polling devices that only have a few interfaces and services and respond very quickly to SNMP requests then the poller has a much easier job. If you’re polling network switches with hundreds of ports and/or something that responds slowly to SNMP then that makes things harder.
The performance of the servers you’re running the pollers on can also make a big difference as you may well need to have lots of poller threads and so a multi-core processor will help a lot. The disk i/o performance of the server(s) that’s running the database and storing the rrd files also has a big impact.
In short, the answer is very much “it depends”. I’ve got a single server that’s doing everything and it’s monitoring around 700 network switches with about 40,000 switch ports plus 1,000+ wireless access points. It’s running fine. I could probably double the number of ports it’s monitoring before it starts having serious performance issues. The server’s got two 8-core Xeon processors and an SSD RAID. If it had magnetic hard disks, though, I think it would be really struggling.
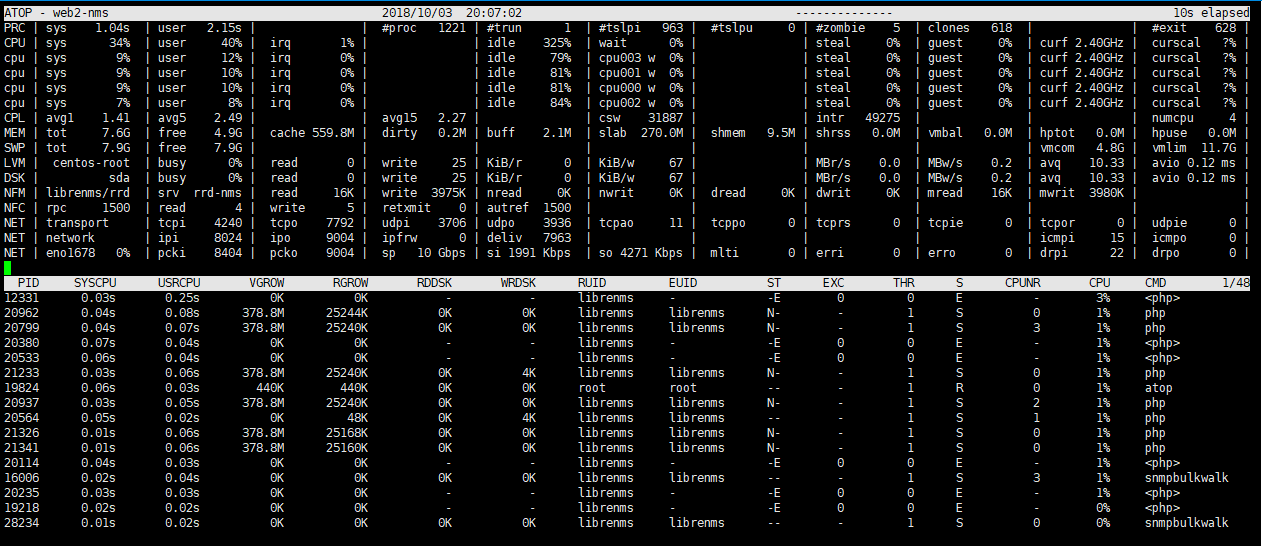
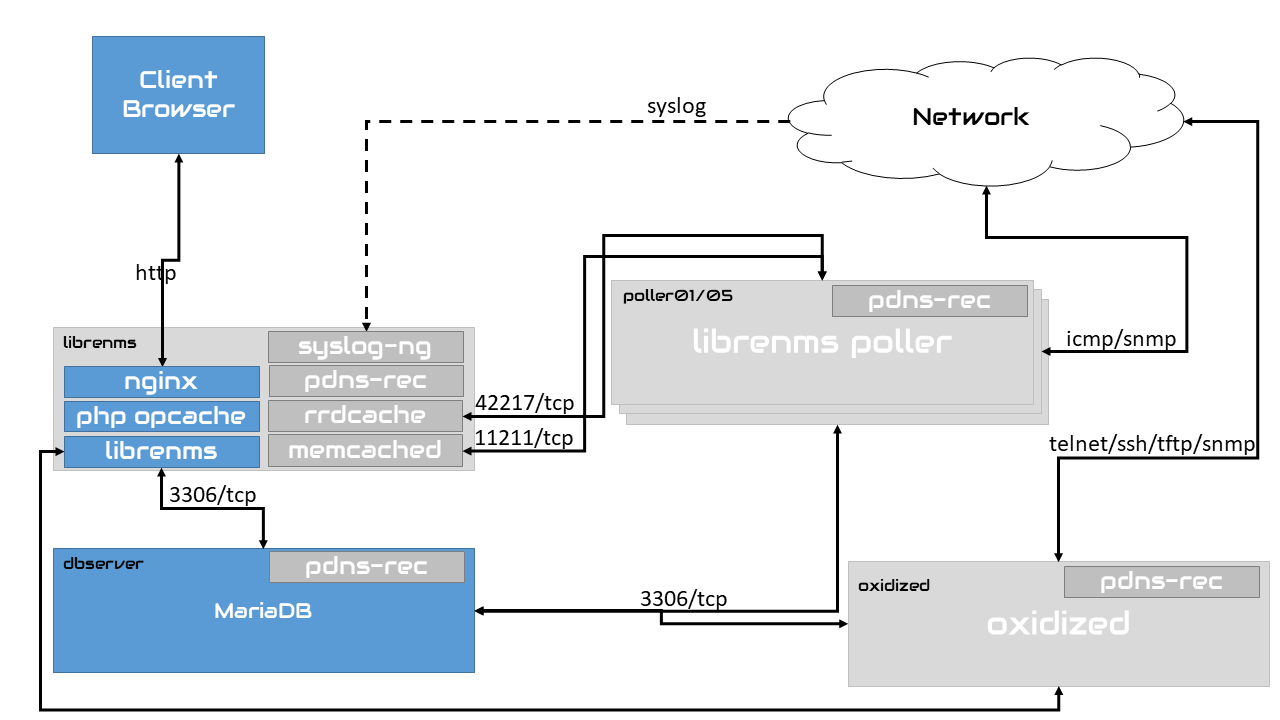
Hi, thanks for replying. Currently, I have been monitoring 500 devices with two pollers running. Soon, I will add up to 2000 devices, it’s all routers with multiple ports and those routers placed across my country. I’d say its a big network currently we monitoring. The pollers have 4core CPU and 8GB memory. RRD stored on a separated VM connected using NFS and RRD Cached. I’m running Memcached also. And I will add 2 more pollers. So, there will be 4 pollers running for 2000 routers. Is it good enough? Or should I improve my VMs specification / add more pollers with the same specification?
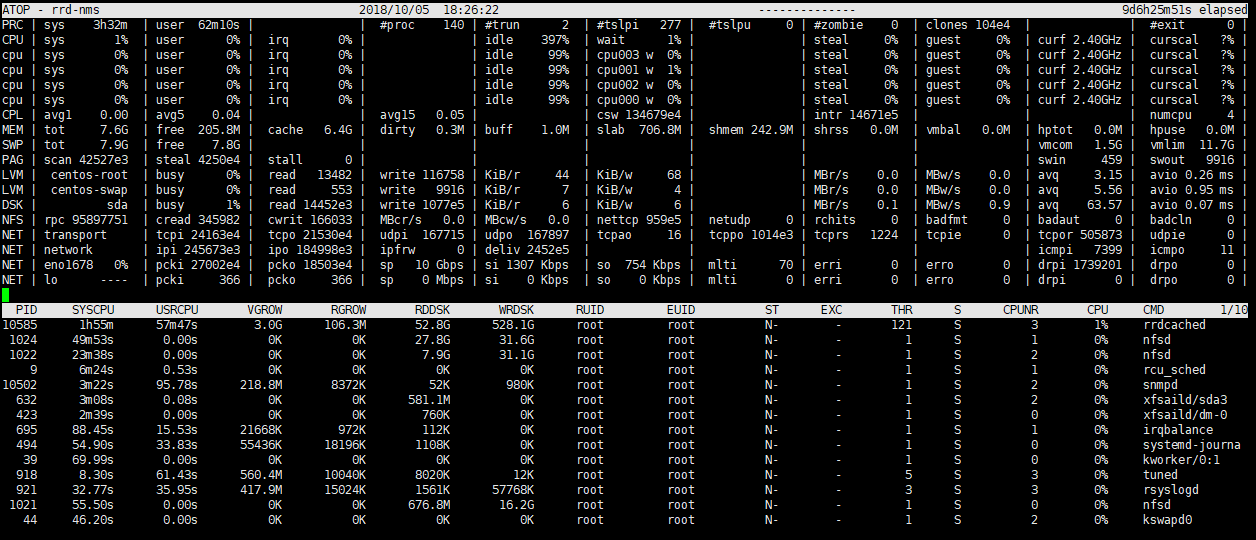
What’s the CPU utilisation like on the current pollers? And what’s the polling time like? Are all the devices being polled quickly or are some taking a long time? Finally, what’s the CPU, memory utilisation and disk i/o like on the servers running the database and rrdcached?
more than 6000 devices with 5 pollers; it depends how many and what kind of SNMP metrics you want to retrieve and collect and also keep in mind that everything is good when network devices are up&running; more issues when you have a lot of down devices due of timeout and retries…
What’s the CPU utilisation like on the current pollers? And what’s the polling time like? Are all the devices being polled quickly or are some taking a long time? Finally, what’s the CPU, memory utilisation and disk i/o like on the servers running the database and rrdcached?
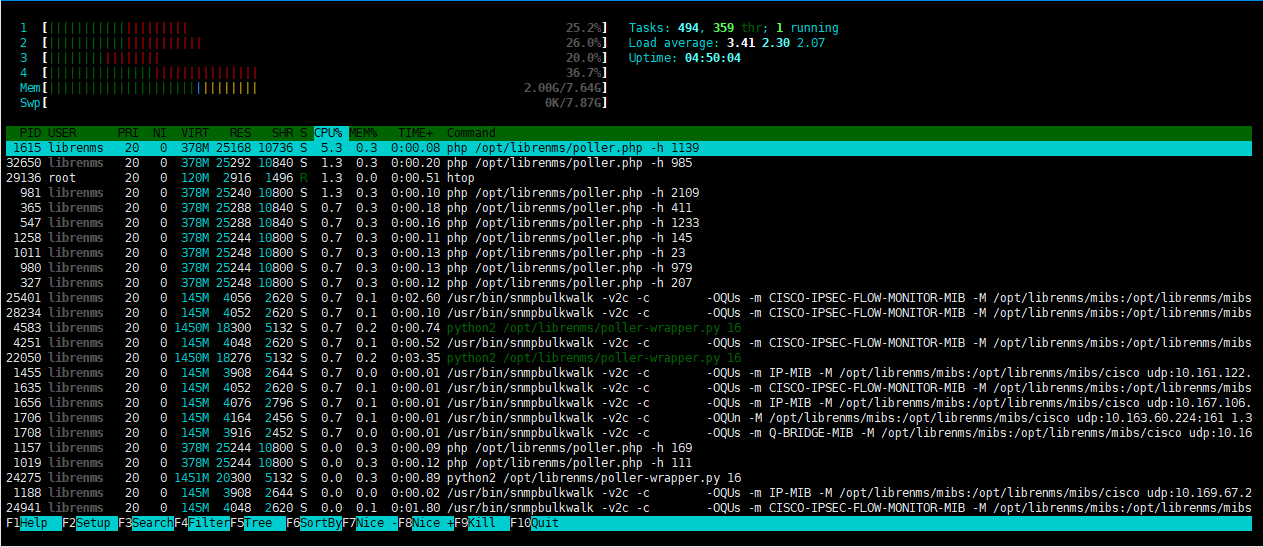
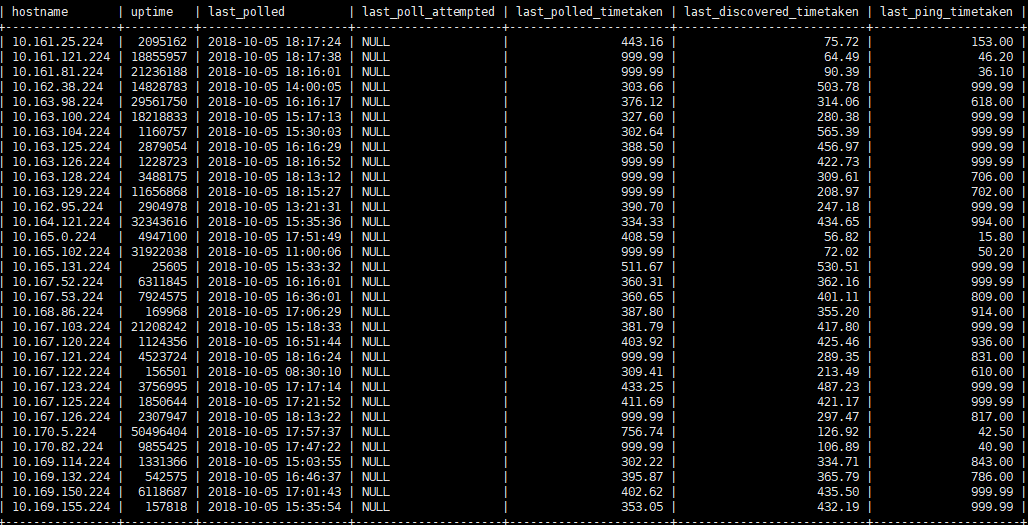
I’ve found that some device takes a long time to poll. There are 2 devices that take 999 second which is about 17 minutes. What is exactly an ideal time to poll a single device(router that has a lot of ports in this case)? And how can i reduce the polling time on a single device?
more than 6000 devices with 5 pollers; it depends how many and what kind of SNMP metrics you want to retrieve and collect and also keep in mind that everything is good when network devices are up& running; more issues when you have a lot of down devices due of timeout and retries…
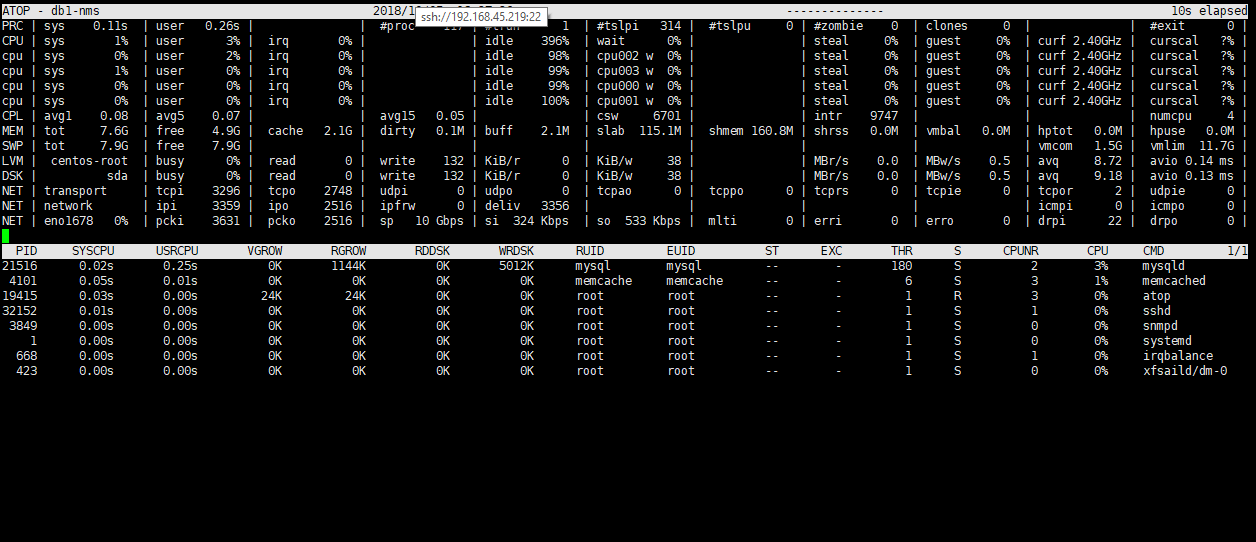
Can you give me the detail on the hardware specification of your server? What kind of device did you monitor? Is there any custom configuration that you use to increase the ability of the pollers?
Each node act a dns cache and resolve names locally.
The polled devices mainly routers and switches from Cisco, Brocade and Huawei; the interface performance collection is enabled just for few interfaces (1 or 2 on each switch; more on routers).
Each node act a dns cache and resolve names locally.
The polled devices mainly routers and switches from Cisco, Brocade and Huawei; the interface performance collection is enabled just for few interfaces (1 or 2 on each switch; more on routers).
Did you have any issue with this environment? What’s the average polling time each device? Did you still find unpolled device?
They just removed some nodes, due of IP migration but still are more than 4000; we have just few devices that are slow on polling (especially during the day due of connection overload); most of the devices have few seconds response time (yours looks very high to me)
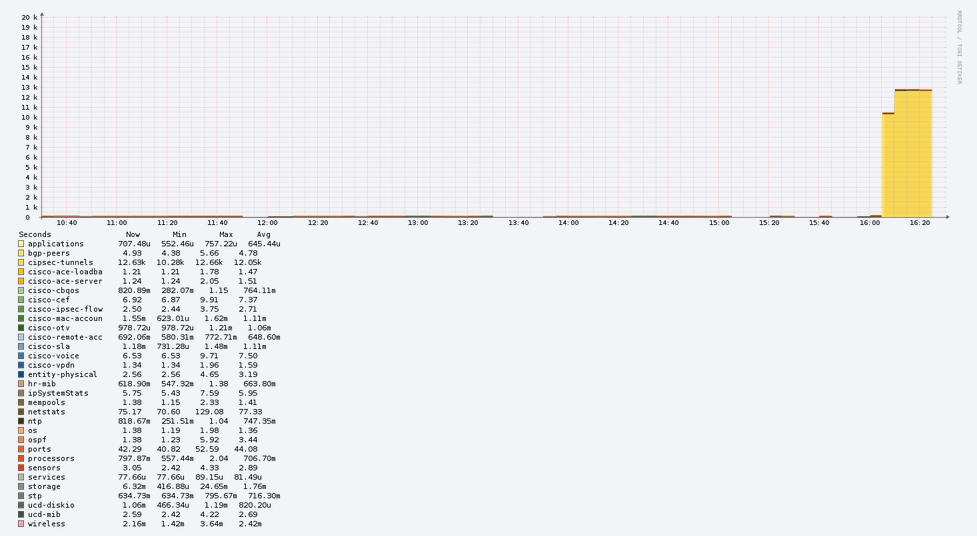
This is current polling statistic for the device mentioned above which has the longest polling time. You can observe there are modules that caused the device to be polled slowly. Maybe I should disable some unused modules.
Did you add any further configuration to the pollers to make the polling time shrink? Can you give me some advice besides increasing my hardware specification?
Well, looks like you spend 99% of the time on the yellow one… what is that? cipsec-tunnels or cisco-ace-loadba? …can you disable it or it is a mandatory check?
Yes, it can be disabled. Yet there are still lots of modules that take time :))
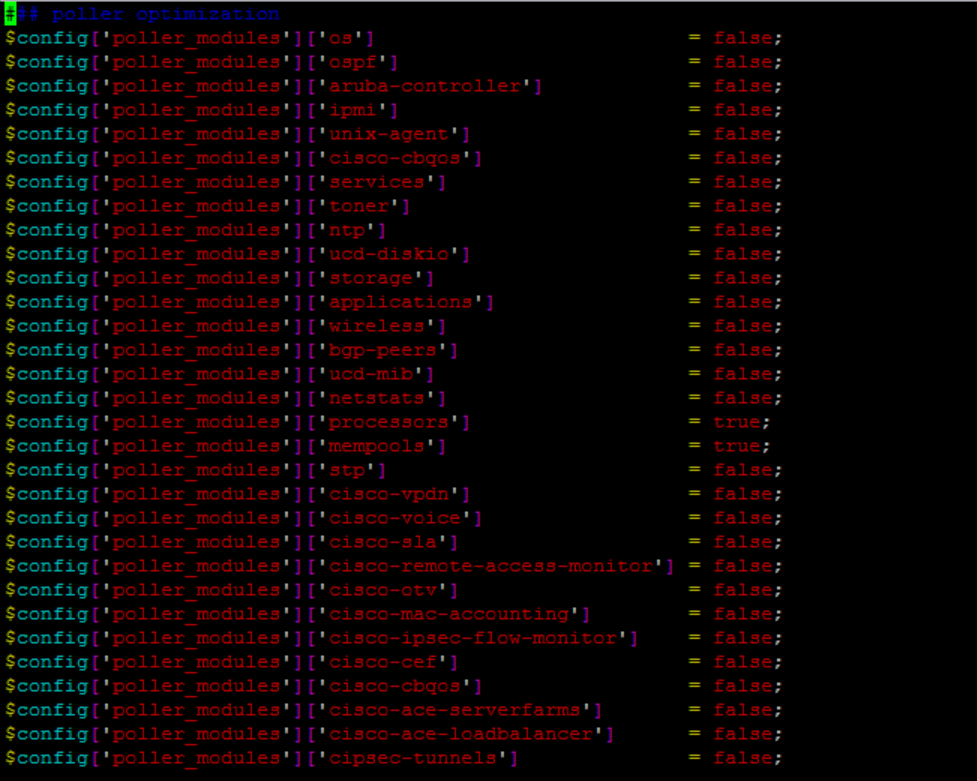
Currently, we monitored Cisco routers. Can you show me what are modules that you enabled like the picture I’ve given above? I’m sorry for asking a favor.
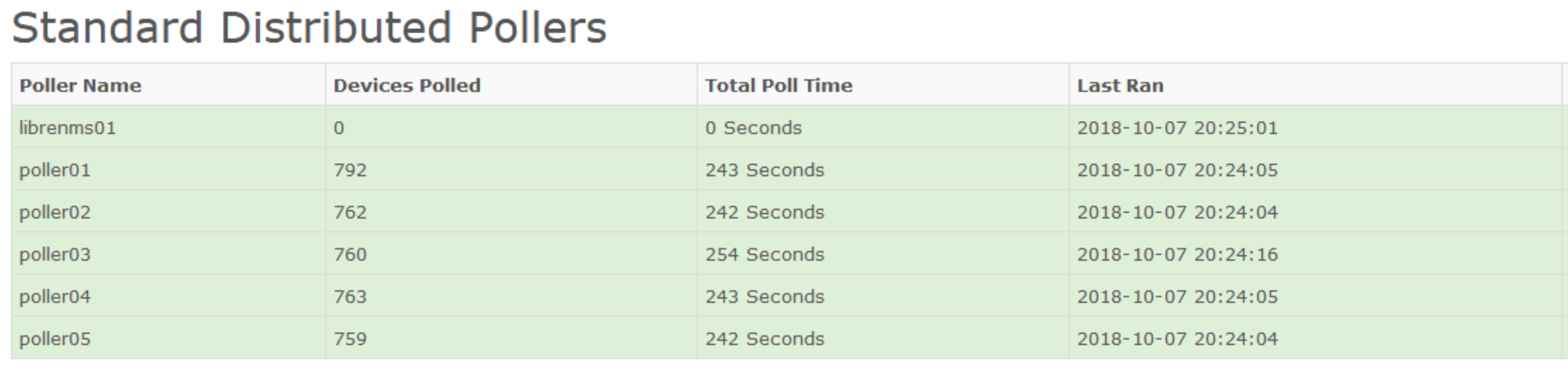
Hi, all. Sorry for the late reply. We manage to solve this problem by disable unused poller modules and increase polling ability by increasing the poller-wrapper thread by 24 and increasing the snmpbulkwalk repeaters to 50. With our current hardware specification and 5 pollers separated into 5 poller groups we are able to poll about 1900 devices within 250 seconds. Thank you for your help!