I’m seeing similar issues with a poller that I added to an existing setup.
There was at some point a version mismatch since I didn’t check out a specific tag when adding the new one, but only that one has the problems. The mismatch was between monthly releases in 24 train so not sure if the database part makes a difference here.
So looks like for me it was caused by Graphite integration, the new poller didn’t have firewall permissions to connect so something was hanging causing the defunct processes. After I allowed the traffic I don’t see the defunct processes anymore!
still no joy here for me, 8 defunct php process overnight after a restart of the librenms dispatcher. im just restarting the service every week or so. not ideal.
Is maintenance running? it should be restarting the process every night. (I don’t think it shows in the unit run time) Or maybe the way the maintenance restarts the process doesn’t clear zombies.
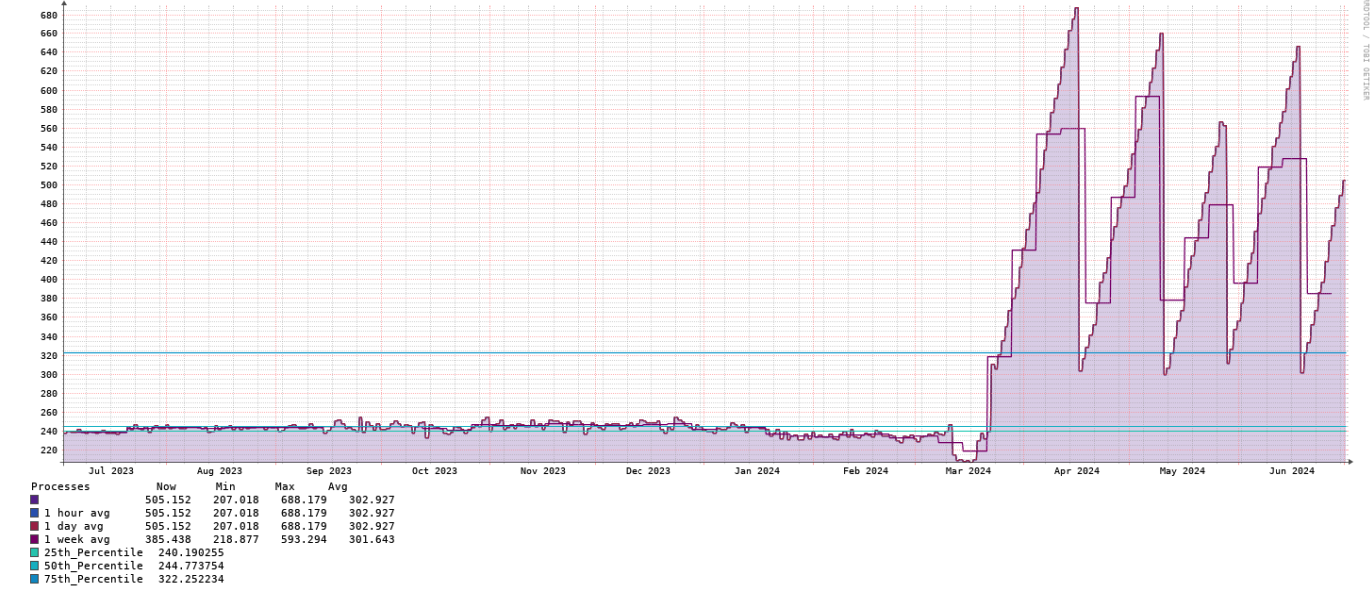
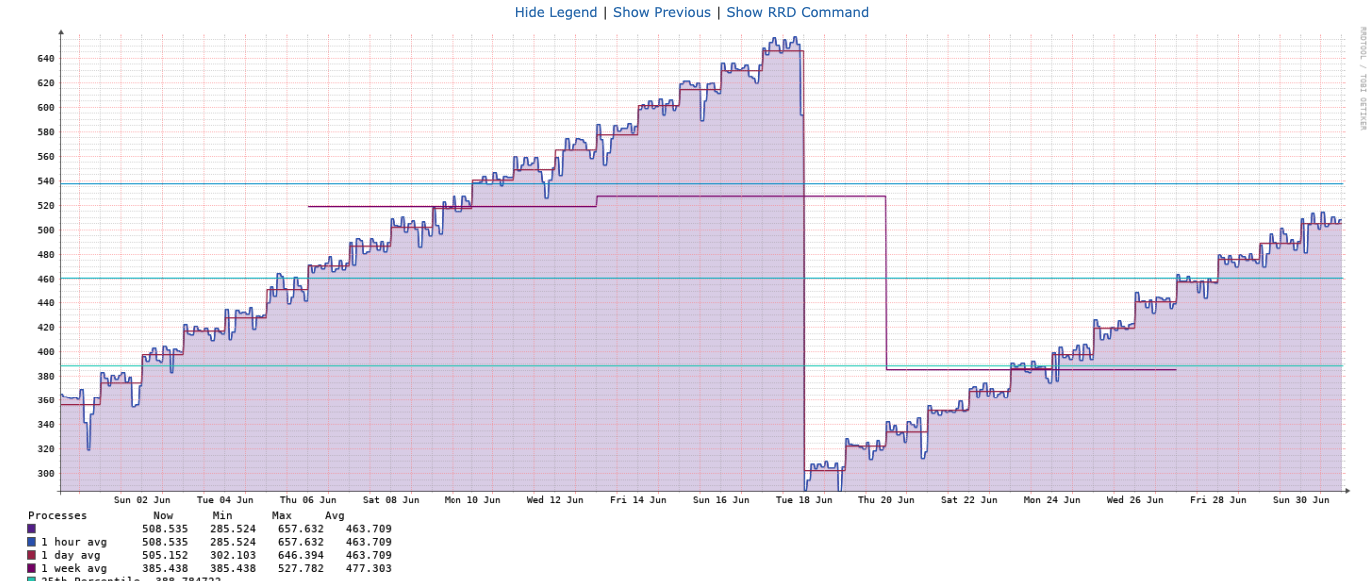
I am also still facing the issue, had to restart the librenms service every 5th day. Maintenance is definitely running as every night defunct process count gets increased. On Day1, when you restart the service, it will be around 70 defunct process in my case as the pollers polls many network devices and on day 2 it will be double and so on.
The above runs at 12pm on my system adn this is when the defunct processes appears. php artisan from my understanding puts libre into maintenance mode @murrant ?
after googling this command and “defunct” i get this article.
now this is above my level of understaning but it appears this command is not terminating these child php processes in the right method. quote…
"The init process (PID 0, such as crond) assumes control over child processes left behind by the primary scheduling process (php artisan schedule:run), which are designed to run in the background (like php artisan command-name with runInBackground).
However, init does not actively take on the responsibility of terminating these child processes. The main scheduling process does not wait for and destroy these background-running child processes, causing them to become zombie processes."
or this person suggest its not waiting long enough?
" I fixed this by including pcntl_waitpid(-1, $status, WNOHANG); in the end of the schedule() function of App/Console/Kernel.php"
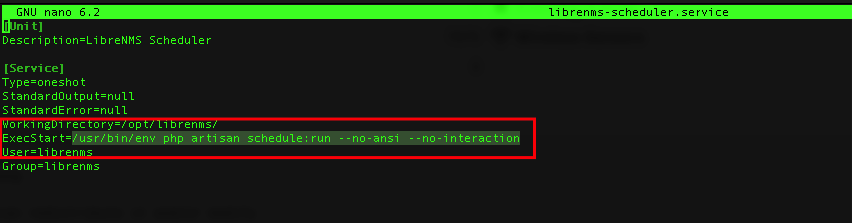
I am still facing the issue but i don’t have librenms-scheduler service at my end.
As suggested by murrant earlier in the thread, we can try below-
I simply restart the services every 10/14th day. I have lot of distributed pollers and all in production , so i can’t make these changes in production directly. If you have test environment then you can try this and let me know
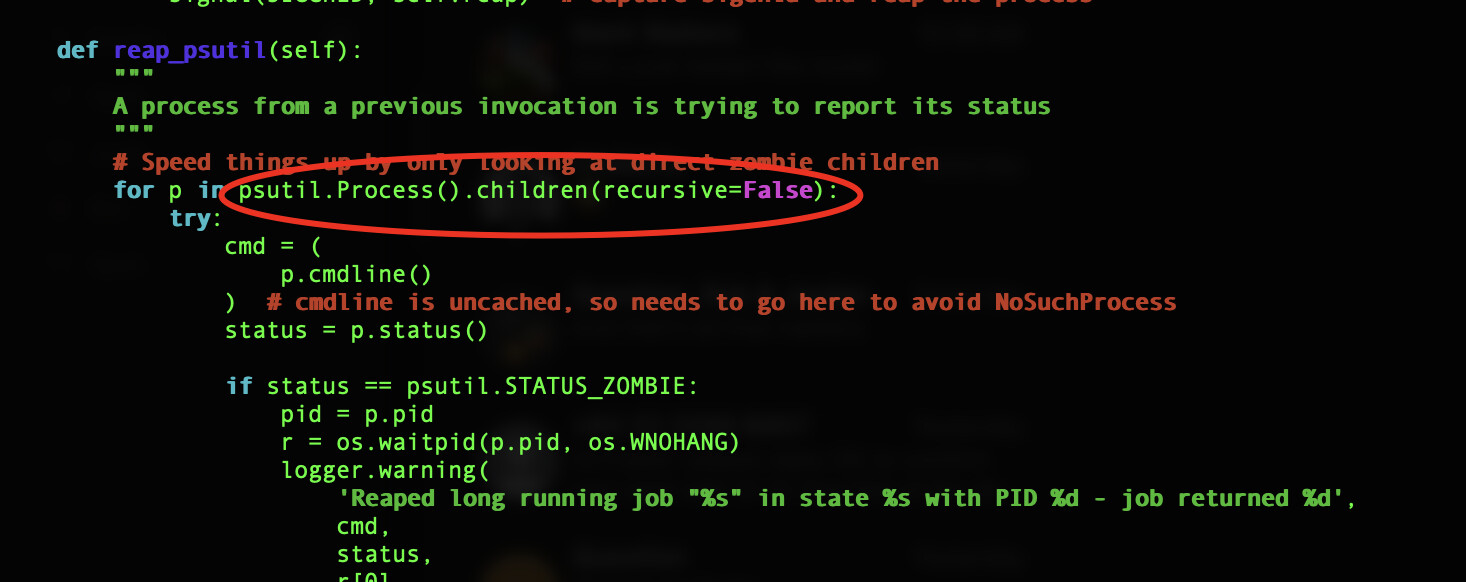
I have just discovered i didn’t have the python module psutil installed. this module is called multiple times in service.py to end pids while the maintenance script is running.
i’ve just installed it with “pip install psutil”. you can check if you have it installed or not with “pip list”. this is mentioned in the requirements.txt and never had a problem before upgrading the OS, i guess it got removed??. the validate script which i thought checked dependencies did not say this was missing…
i’ve just installed it so see what happen in 20 hours or so when maintenance runs again.