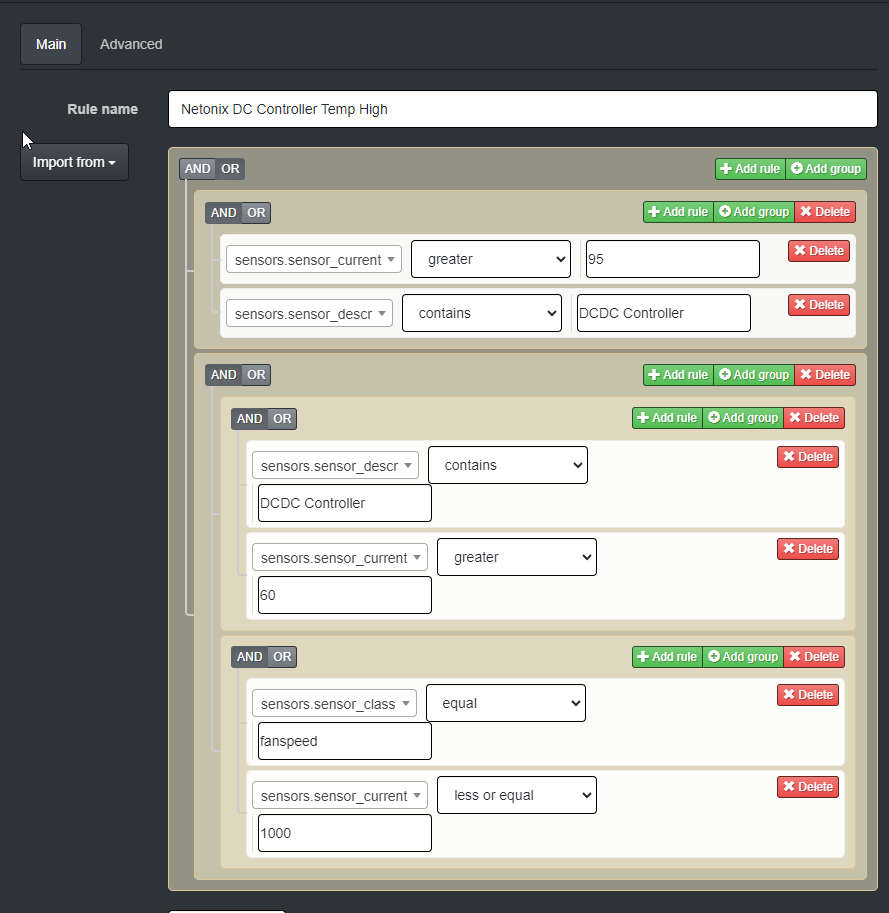
I’m trying to create an alert for a switch that checks a specific temperature sensor to see if it’s over a value, or if the temperature sensor is over a value and the fanspeed sensor is less than a value at the same time. I suspect that I’m just not knowledgeable enough with SQL queries but this is what the alert rule and query looks like.
SELECT * FROM devices,sensors WHERE (devices.device_id = ? AND devices.device_id = sensors.device_id) AND ((sensors.sensor_current > 95 AND sensors.sensor_descr LIKE ‘%DCDC Controller%’) OR ((sensors.sensor_descr LIKE ‘%DCDC Controller%’ AND sensors.sensor_current > 60) AND (sensors.sensor_class = “fanspeed” AND sensors.sensor_current <= 1000)))
Each of these conditions (sensors.sensor_descr LIKE ‘%DCDC Controller%’ AND sensors.sensor_current > 60), (sensors.sensor_class = “fanspeed” AND sensors.sensor_current <= 1000) works standalone but not when I try and combine them with AND, which is why I think that it’s something I’m not quite understanding in the query.
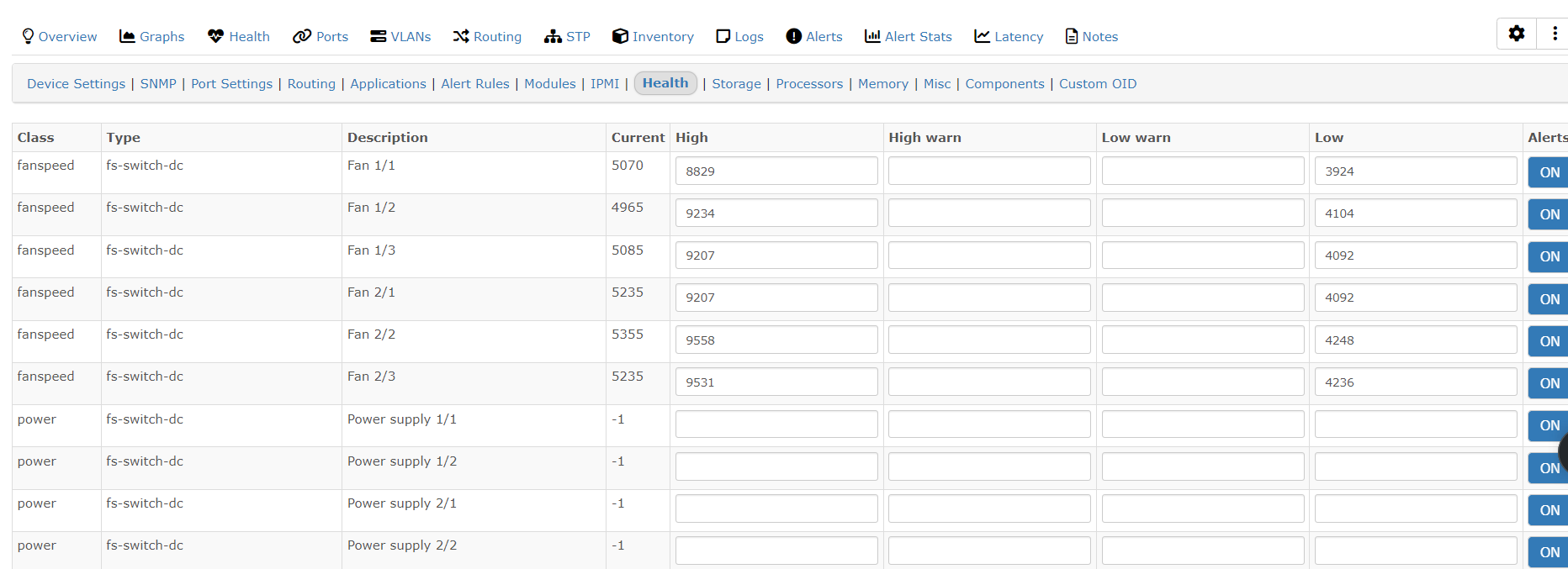
It could be easier go to the switch > settings > health, and then set the min/max values in there for the fan speed, temps ect. When those specific health alerts trigger then it triggers the default sensor alert
I considered that but discounted it originally because we’d have to update every switch we have and ensure folks remember to update those when adding a switch.
The problem we’ve run into is we’ve had a couple of these switches fans fail and we didn’t realize we had a problem until it got hotter out and the cabinet temps brought the controller temps up to the point where the switches started shutting off the PoE.
My thought was to create a dual purpose alert where it checked to see if the fan was not spinning ( < 1000 rpm ) and the temp was over a certain point ( > 60c ) to notify us that the fan failed, or if a switch was over an acceptable temp ( > 90c ) on the controller. The reason for doing it this way is because the fans on these devices will stop when they aren’t needed, so we can’t just alert on a fan stopped.
Now that I’m thinking about it though, maybe we can do something along the same lines with the health min/max values, I’ll have to tinker with it a bit.
I do not seem to be able to create new topics (maybe its disabled for new users but for some reason i do not have “new topic” button) so i am forced to use some existing topic and since my question is related to alerts i am posting it here…
I am testing LibreNMS and i have one major problem. LibreNMS groups all alerts of specific type for specific device into single notification. For example if multiple ports go down or multiple BGP peers go down or multiple state sensors are critical etc it issues one notification and lists all of them there. I actually like this part. But the problem is that if some alert type is raised and notification for it sent, it does not send any more notifications if something changes with that alert (more ports go down or some of them come up, more BGP peers go down or up, more state sensors go critical etc…)
Is this normal? I know that LibreNMS should have some “got worse” and “got better” logic, but it just does not work for me. Is there something that i might be doing wrong?
One “workaround” is to just schedule some interval in alert rule to keep resending notifications and then information will be updated if it changes, but this is not what i want. I dont want to receive notification spam and track manually, if something have changed. I want LibreNMS to send me 1 notification if alert activates and then send more notifications if alert “got worse”, “got better”, or recovered completely. I would imagine that this is how it should work, but for some reason it just does not behave in that way.
There is no additional emails if the alert gets worse or better, just that if it meets the condition to email out (taking note of max alerts and intervals) and a recovery if enabled to do so if the conditions no longer meet.
You could setup multiple alerts based on severity and as the conditions worsen it will then trigger the next alert to email you, that would be the best solution i can see.
Thanks for your reply. But then what is this “got worse” and “got better” logic supposed to be about? I imagined that if more items are added to the alert then it will trigger “got worse” notification and if items are removed from alert then it will trigger “got better” notificaton. But if you are indeed correct and changes with alert items are not supposed to trigger any notifications, then unfortunately that is kind of a deal breaker for me (because as far as i understand LibreNMS does not allow ungrouping alert items either )
“You could setup multiple alerts based on severity and as the conditions worsen it will then trigger the next alert to email you”
What do you mean by that exactly? Lets say i have an alert for BGP peerings or some network interfaces, how can i create multiple alerts so i can receive notifications when second BGP peer goes down or second port goes down etc…
My understanding is the ‘got worse’ and ‘got better’ is used around the acknowledgement of an alarm. I’ve not seen in my use of LibreNMS that it re-generates alert transports based around a condition getting worse or better. Happy to be proven wrong.
You could setup multiple BGP alerts that triggers based on specific details, for example for BGP peer #1 have a rule configured just for that bgp peer and you can specify this by using bgpPeers.bgppeerRemoteAS or bgpPeers.bgppeerRemoteAddr for example, and that way if that specific peer drops then then that specific alert for that specific bgp peer will trigger. Then do the same for the next BGP peer and alert ect. Sure you’ll end up having to setup and maintain multiple alerts for each different bgp peer but its basically what I’m saying by a way to receive multiple different BGP alerts from a specific device.
If you set your alerts to keep emailing you on specific times such based on intervals, the body text should tell you what’s down but would mean you have to keep reading each email coming in to see if there is change of condition.
Ok, thanks for clarification. Maybe i should make a feature request then, i’m kind of amazed that this is not a feature (default behavior) already, but i guess i will stick with Observium for now
We’ve gotten ‘got better/worse’ alerts from librenms before. I believe as long as you don’t click the “Acknowledge until clear” toggle it will send these out.
Back on my topic, I solved the fanspeed/temp check with chatgpt and a custom SQL query. For the first portion of the alert, I just created a second alert for the Temp High portion. Probably not the most efficient query, but it does the job.
SELECT devices., sensors_fanspeed., sensors_dcdc.*
FROM devices
JOIN sensors AS sensors_fanspeed
ON devices.device_id = sensors_fanspeed.device_id
AND sensors_fanspeed.sensor_class = ‘fanspeed’
AND sensors_fanspeed.sensor_current < 1000
JOIN sensors AS sensors_dcdc
ON devices.device_id = sensors_dcdc.device_id
AND sensors_dcdc.sensor_descr LIKE ‘%DCDC Controller%’
AND sensors_dcdc.sensor_current > 60
WHERE devices.device_id = ?;
I tested some more and yes, “got worse/better” notification will be indeed sent, but only if you acknowledge that alert first. If you do that and items are added to the alert (or removed), then it will automatically remove the acknowledgement and send out “got worse/better” notification. I’m starting to wonder, is this really desired behavior (that LibreNMS does not send out “got worse/better” notifications for unacked alerts) or maybe a bug? Because for me this kind of renders monitoring solution unusable and i can’t imagine that someone would actually want it to behave like that. Because as i noticed, not only does it not send out notifications, but this does not even go to alert history so you are totally in the dark what went on once alert went active (until you finally had a chance to acknowledge it).
Oh, and btw, now i have “new topic” button I think it should be spelled out clearly, that new users can not create new topics for x amount of time or whatever the case… it was pretty frustrating to not understand how the hell am i supposed to create new topic to ask for help and what am i doing wrong.
Another way to look at it, if there was a power outage and a UPS switches to battery, the capacity and time remaining would start decreasing or in other words will be constantly ‘getting worse’, I wouldn’t want it to continually tell me its ‘getting worse’ so not all scenario’s you would want to introduce a ‘get worse’ or ‘get better’ by default. Another example would be if you had an alert for high latency and if the latency is bouncing around in theory that’s ‘getting better’ and ‘getting worse’ so again not something you want constant alerts for.
The acknowledgement to me makes sense because it’s you acknowledging the current state and it would then alert you again if that state changes knowing you knew of its previous state.
I don’t think those are good examples. In those cases it is the single item/metric that is changing and you would not get “got worse/better” alerts, LibreNMS “got worse/better” logic is not about single item/metric, but about NEW items/faults being added to (grouped) alerts. So in case of UPS battery drainage or some latency it is either under threshold or not and there is no “got worse” logic if those metrics change.
This example would be appropriate if lets say this UPS has multiple power feeds (pretty realistic) and one of the feeds fail, then alert “UPS POWER FAILED” will go active and in it will be listed items “Power feed nr 1 failed”, that notification will be sent. Then lets say 10 minutes later another power feed fails but since this alert is already active you will not be notified. Then after another 15 minutes third power feed fails, again you will not be notified. Then one of the failed power feeds comes back up, you will not be notified etc… you are totally in the dark what is happening after first fault.
But lets say you have a chance to go into LibreNMS and ack the alert after first power failure and after that second power feed fails, then you will indeed receive a notification, that “UPS POWER FAILED” alert “got worse” and second feed went down (second item was added to the alert) “Power feed nr 1 failed”, “Power feed nr 2 failed” etc…
In case of Observium every item is handled as separate alert/notification, but because LibreNMS groups all items into one alert, this “got worse/better” logic is needed when new items are added or removed.
I and still can’t imagine that someone would not want to be notified about those changes (new faults added or some of them recovered). It is not realistic to imagine that you are behind your computer at all times and ready to ack every alert.