Did you find a solution Joe and can you share this with me?
I also have regular false positives and I am searching for the same solution.
Devices needs to be rechecked after an interval before sending out the alert.
Did you find a solution Joe and can you share this with me?
I also have regular false positives and I am searching for the same solution.
Devices needs to be rechecked after an interval before sending out the alert.
Actually no, I haven’t found a solution for this and after putting a lot of time into this, I gave up. IMHO, this is something that differently should be built into LibreNMS.
I would love to have this working and it’s the only thing lacking in my LibreNMS setup.
how is the device being reported down icmp or snmp down status?
By SNMP:
Alert for device 10.4.0.22 - Devices up/down
Severity: critical
Timestamp: 2017-08-03 20:20:06
Unique-ID: 1481
Rule: Devices up/down
Faults:
#1: sysObjectID => enterprises.2011.2.23.203; sysDescr => S5700-10P-LI-AC
Huawei Versatile Routing Platform Software
VRP ® software,Version 5.170 (S5700 V200R010C00SPC600)
Copyright © 2007 Huawei Technologies Co., Ltd.;
Alert sent to:
Try this,
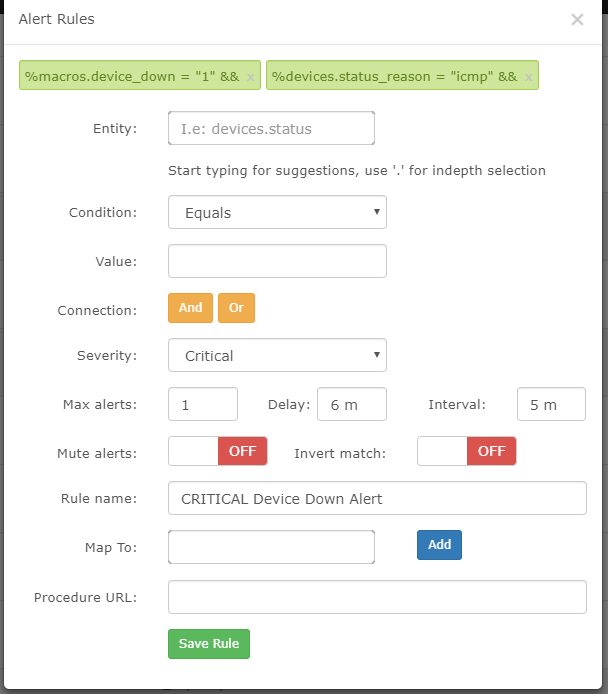
disable the default “up/down” alert rule and add this alert as your “device down alert”.
%macros.device_down = “1” && %devices.status_reason = “icmp” &&
this should help with false positives devices being marked down.
Thank you for this quick helpful response.
An error I created was at least noticed and mailed as well with the new alert rule. I have disabled the old rule, and enabled the new one. I will let this thread know after the weekend what the results are.
At least this is not hurting me 
@joe_v LibreNMS has no concept of retrying a down device outside of a poller interval so the best you will get is setting the delay to 6 minutes so that you would hope two polls would have happened.
@murrant - Does your new python poller service do down device retry before the next poller interval?
@laf yes, by default it is 1 minute, configurable.
Thanx for the input guys. As promised here are my results from this weekend.
Changing the rule to:
%macros.device_down = “1” && %devices.status_reason = “icmp” &&
Did not seem to help. I also changed the cron to:
33 */6 * * * librenms /opt/librenms/discovery.php -h all >> /dev/null 2>&1
1-59/5 * * * * librenms /opt/librenms/discovery.php -h new >> /dev/null 2>&1
2-59/5 * * * * librenms /opt/librenms/cronic /opt/librenms/poller-wrapper.py 8
15 0 * * * librenms /opt/librenms/daily.sh >> /dev/null 2>&1
* * * * librenms /opt/librenms/alerts.php >> /dev/null 2>&1
###*/5 * * * * librenms /opt/librenms/poll-billing.php >> /dev/null 2>&1
###01 * * * * librenms /opt/librenms/billing-calculate.php >> /dev/null 2>&1
*/5 * * * * librenms /opt/librenms/check-services.php >> /dev/null 2>&1
So not all scripts start at the same time. This seems to help a bit.
Furthermore, as the post above here suggested, I changed interval timers a couple of minutes ago.
Max: -1
Delay: 360
Interval: 300
Lets see if I can get this stable.
Some background information:
False positives happened before, but I was never able to pinpoint where they where coming form. I didn’t have any false positives for some weeks till last thursday. Then they started again (multiple per day)
I think Librenms is not the real problem. The setup is located on a cloud-VM (google cloud), and Connected with a ASA with IP-sec to my network. Tunnel is steady, server seams steady, uptimes of server, IP-sec is several month.
This is why I’m trying to spread the con. It is a VM, and resources are spread.
What new poller service? Is it in the auto-updates?
Possible new SNMP interface <= this one … unfinished I guess.
you could try adding this to config.php and adjusting it for ping timeouts.
$config[‘fping_options’][‘retries’] = 5;
$config[‘fping_options’][‘timeout’] = 1000;
$config[‘fping_options’][‘count’] = 4;
$config[‘fping_options’][‘millisec’] = 1000;
I already had those in my config:
$config[‘fping’] = ‘/usr/bin/fping’;
$config[‘fping6’] = ‘/usr/bin/fping6’;
$config[‘fping_options’][‘retries’] = 5;
$config[‘fping_options’][‘timeout’] = 1000;
$config[‘fping_options’][‘count’] = 4;
$config[‘fping_options’][‘millisec’] = 1000;
ohhh ok. 
I have increased the delay to 6 minutes and it does seem to help a bit but it doesn’t fix it completely. I’m still getting false positives.
When does this new poller system get release? I sounds like it might be a better fix.
It’s not even made it to PR stages yet.
@murrant may be able to give you some idea.
The new python service has a file handle leak when it self updates to figure out still. I got tired of looking at it, so it is on pause for a bit.
Hey there. Don’t know if this still actual.
My deсision is Custom SQL Query
Here is my string:
“for devices been down for 3 days and more”
SELECT * FROM devices WHERE (devices.device_id = ?) AND devices.status != 1 AND HOUR(timediff(now(), last_polled)) >= 72;
am i right? or i missing something?
might be helpful for someone
Hi,
I found this thread when trying to achieve the same thing and found a SQL Query that works good for me.
SELECT * FROM devices WHERE (devices.device_id = ?) AND (devices.status = 0 && (devices.disabled = 0 && devices.ignore = 0)) = 1 AND TIME_TO_SEC(timediff(now(), last_polled)) >= 1800;
This triggers after 1800 seconds of downtime (30min) but can be changed to whatever.
Hope it helps.