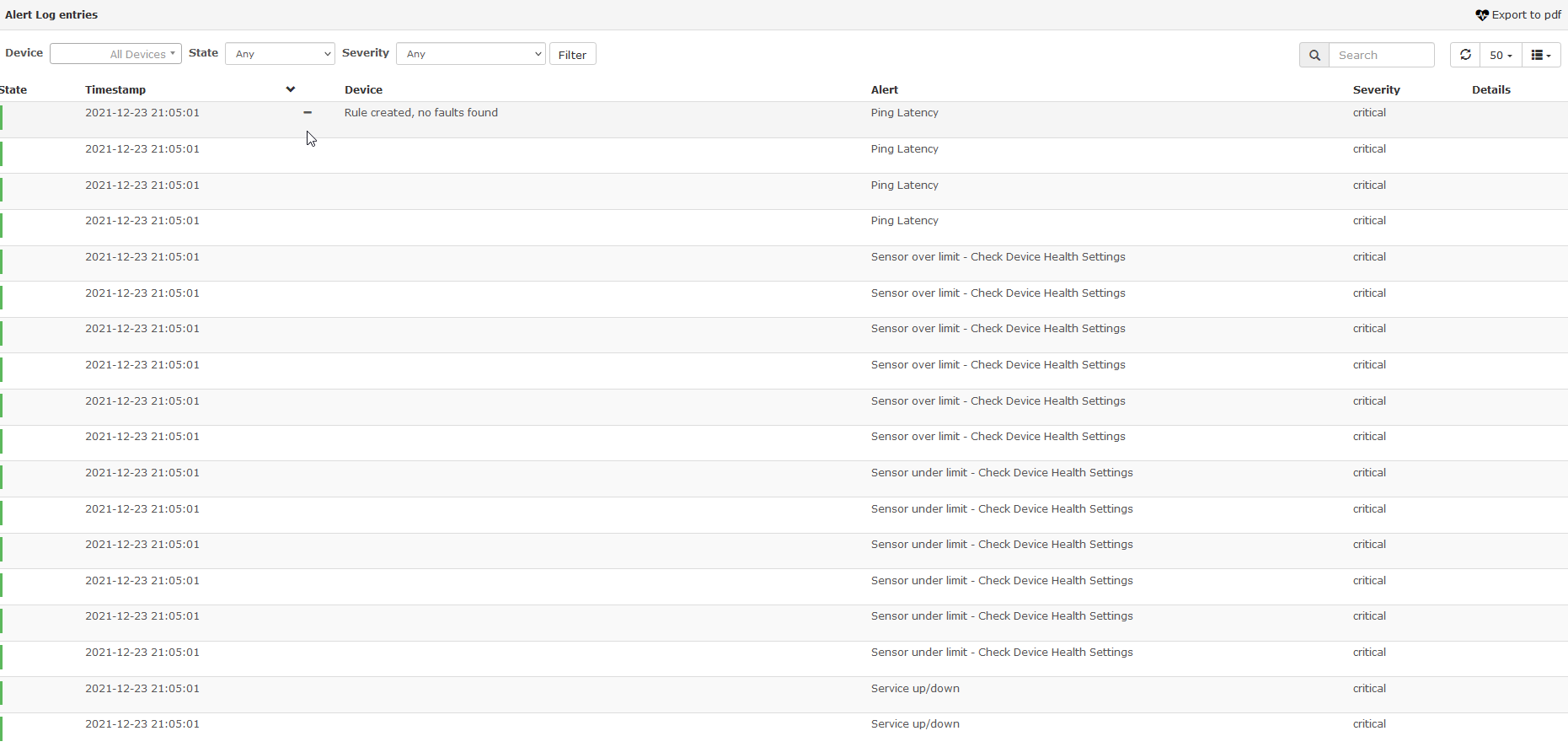
After Upgrading to the latest docker image, my alert log keeps growing wtih “recovered state” events but I feel this seems like a bug. I attach a screenshot of the problem
It’s really hard to offer any advice when you’ve not provided any info such as the alert rules triggering these. Also look at the event log for one of the devices to see.
Those alerts correspond to every single rule, many of them are the default ones (Ping Latency, SNMP, Device reboot, sensors. Of course, I could post the rules if it’s helpful
The event log does not contain any relevant information to the screenshot above. I see nothing abnormal there, mostly service status logs, but nothing to do with the “recovery alerts”. Also, if you take a closer look at the screenshot I uploaded, In the “Device column”, all I see in every line is “Rule created, no faults found”
I downgraded to 21.11.0, the behaviour was the same.
I then downgraded to 21.10.2 and the problem disappeared, the behaviour in the event log is the expected.
I forced some CPU alerts to check this
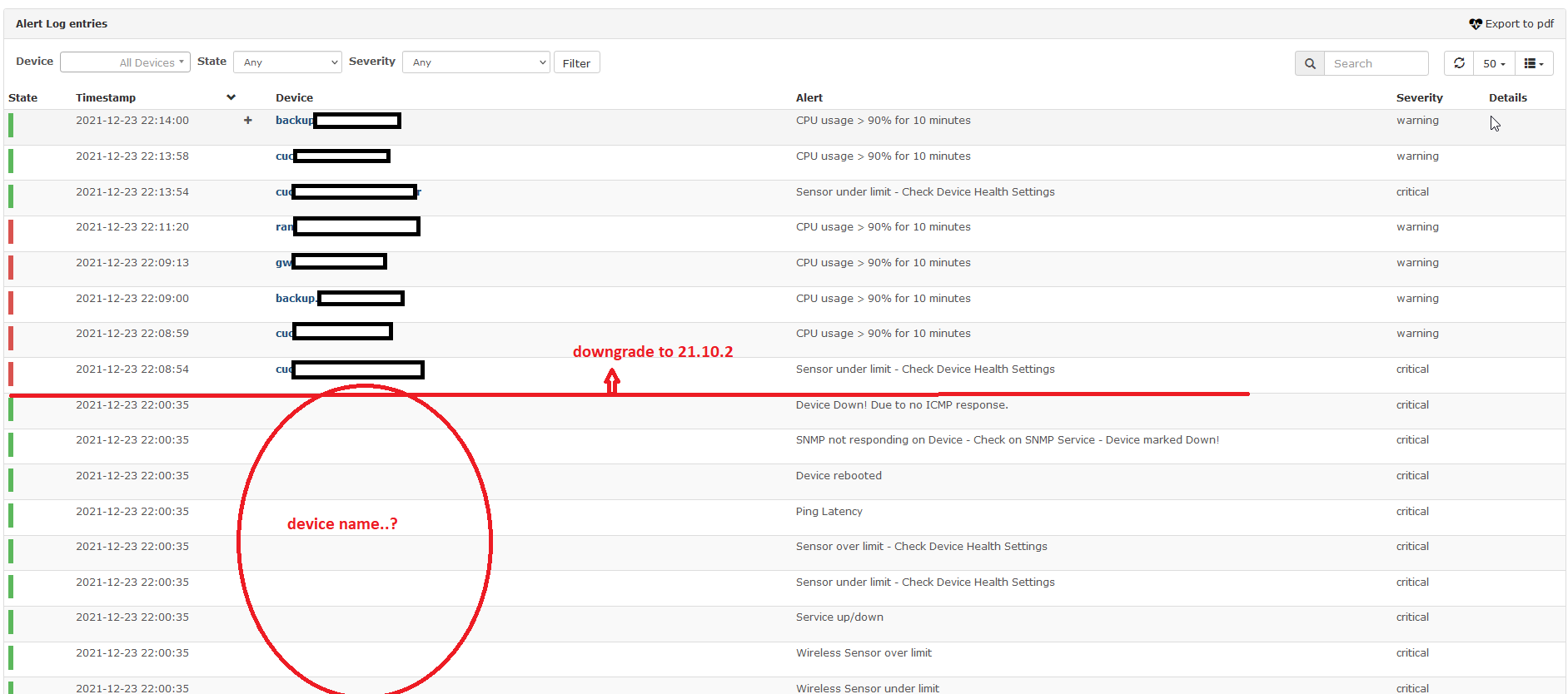
The issue is also described in #13424
As suggested by k0079898, I reverted the change made in commit 13348
by commenting out lines 200-203 in : includes/services.inc.php and these “bad” alerts disappeared.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.