I am experiencing an issue with my alert rules where if I have the rule set to the following:
Max alert = 1
Delay = 1m
Interval = 0
Recovery Alerts = ON
I will receive the initial alert, but it does not send a recovery alert. However, if i set the “Max Alert” to “2”, I do receive a recovery alert – but it also fires two down alerts if the device is down long enough that it does not recover within the initial delay period.
This behavior is odd to me and I am wondering if it is a potential bug or a configuration or understanding issue on my end.
Here is the copy/paste from my validate.php:
librenms@s-libre-cc:~$ ./validate.php
===========================================
Component | Version
--------- | -------
LibreNMS | 23.11.0-6-ga61c11db7 (2023-11-22T17:53:19-08:00)
DB Schema | 2023_11_21_172239_increase_vminfo.vmwvmguestos_column_length (274)
PHP | 8.1.2-1ubuntu2.14
Python | 3.10.12
Database | MariaDB 10.6.12-MariaDB-0ubuntu0.22.04.1
RRDTool | 1.7.2
SNMP | 5.9.1
===========================================
[OK] Composer Version: 2.6.5
[OK] Dependencies up-to-date.
[OK] Database connection successful
[OK] Database Schema is current
[OK] SQL Server meets minimum requirements
[OK] lower_case_table_names is enabled
[OK] MySQL engine is optimal
[OK] Database and column collations are correct
[OK] Database schema correct
[OK] MySQl and PHP time match
[OK] Active pollers found
[OK] Dispatcher Service not detected
[OK] Locks are functional
[OK] Python poller wrapper is polling
[OK] Redis is unavailable
[OK] rrd_dir is writable
[OK] rrdtool version ok
`Preformatted text`
thanks in advance for any ideas or assistance. I should note that i’m experiencing this issue regardless of transport method. Slack / email / pushover all are giving me the same results as described above.
Laf – thanks for the suggestions. I dug through some event logs and alert logs and the results are a little bit intermittent, on the event log I see a few alerts that fired (…along with the transport) with the matching recovery’s, and some that have just the fired alert. however, when i look at the specific device alert history, i see the alert and matching recovery event.
Presently i’m only running two active alerts: ping latency > 300ms and your standard “device is down” alert (macros.device_down = 1 AND devices.status_reason = “icmp”). I just double checked that both rules are set to “max alert = 1” with recovery “on”. I’m going to watch it another day or two and post the results.
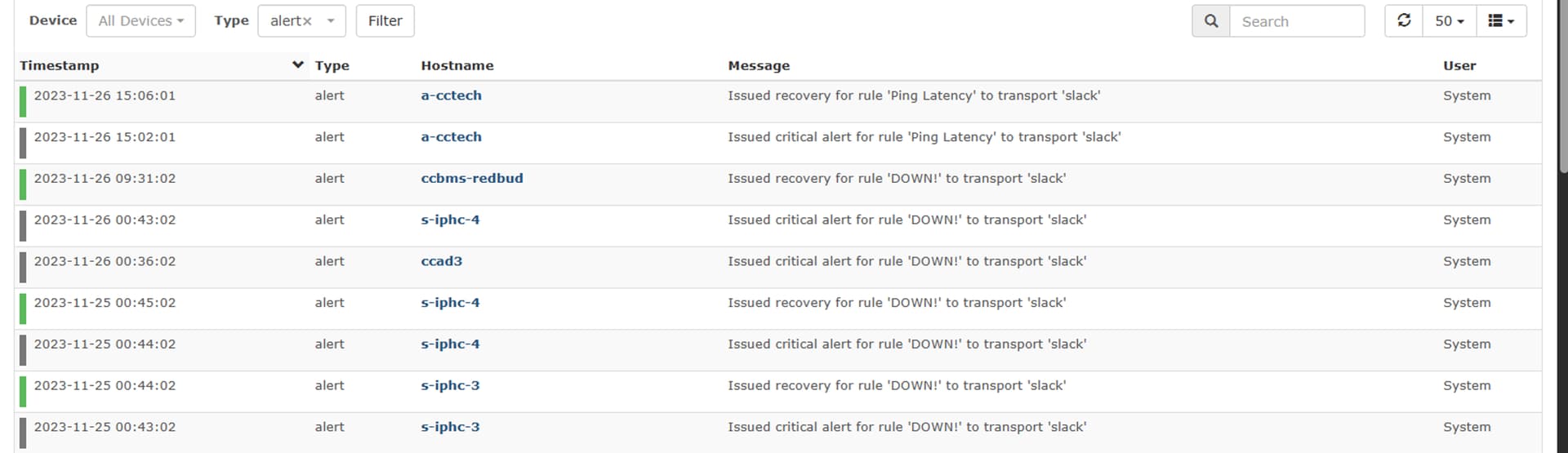
for what it’s worth, here’s a screenshot of the most recent alerts filtered from the event log (…no need for me to scrub the hostnames, they’re all internal devices…). the “ccbms-redbud” recovery event is legit from a previous outage. you can see, however, that ccad3 fired a alert but never a recovery (…in reality the device recovered within 60 seconds) – maybe thats a clue. the alert fired and recovered during the first interval/delay cycle – like it was a blip on the radar. that’s still a concern though because it tells you there was a blip but leaves you hanging.
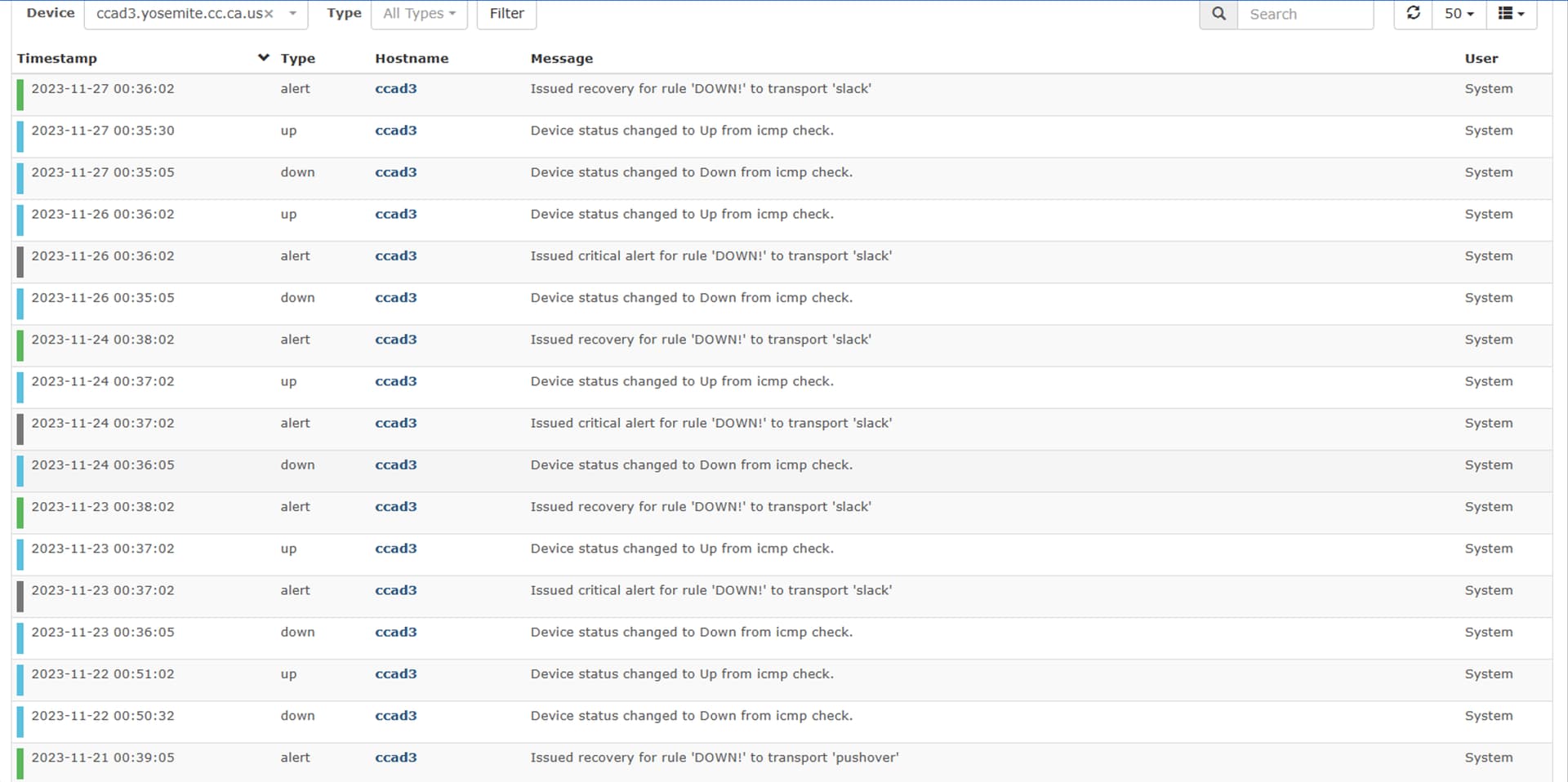
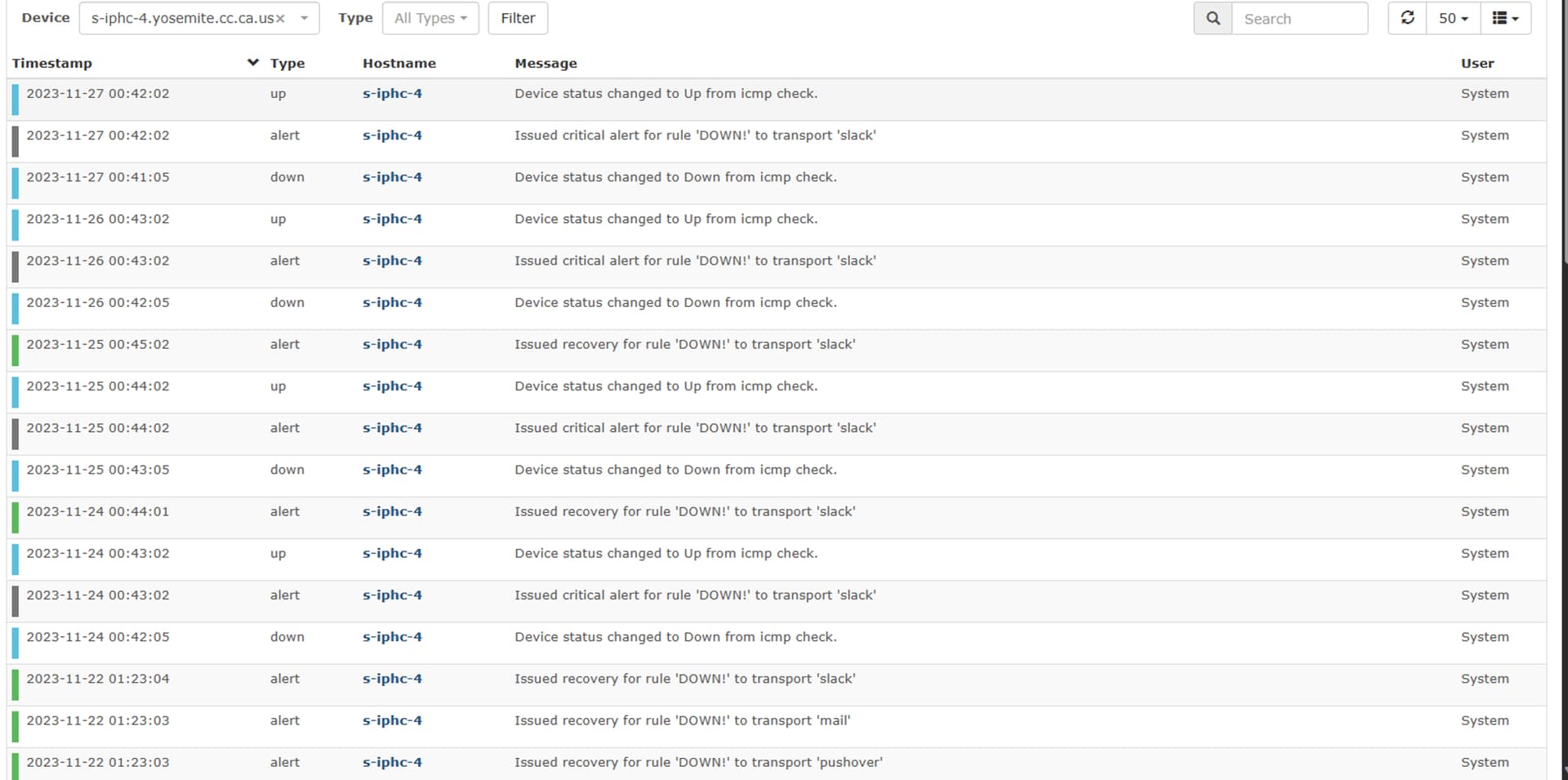
Ask and ye shall receive. here are event log snips from “ccad3” and another device “s-iphc-4” (edit: i’ll upload that image in a second reply since i’m a “new” user). both are ping only devices but I’m seeing this behavior regardless if its a ping only, or a full-fledge SNMP polled device.
it seems to be intermittent and tied to flap/blip events. if the device recovered prior to ever sending an alert, i can live with that. however firing an alert w/transport and no matching recovery w/transport could cause doubt in if the device is truly recovered or not.
So the order of events for ccad3 shows everything correctly, s-iphc-4 is missing one recovery alert as you can see. However what’s odd is the events aren’t in timestamp order. It might be worth checking the time across all the servers you are running for LibreNMS to see if anything is slightly out.
I must be blind – can you tell me which events are not in timestamp order? the screenshot is sorted by timestamp so i’m looking at that column as i type this. unless you mean the order of events themselves is not correct (like a recovery being fired before the alert itself).
regarding the time across servers – i’m currently running LNMS on a single box which has the correct time and date.