I’m working on alert templates using Telegram transport.
We notify admins when a BGP session goes down, a filesystem reach more than certain mark, etc. We make a list by iterating faults to give more information to sysadmin
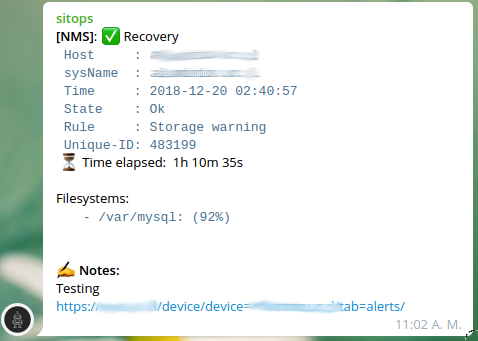
A filesystem was at 92% of usage when alert was triggered. Then when the problem was resolved, the filesystem was at 65%, but the recovery message still say 92%. I would like to notify admin team, that the problem was resolved and the filesystem is now at 65%. I thing that this can’t be possible just iterating the faults list.
Is there a way to do this? Or may be a feature request?
Thanks to both of you for these. I’ve updated my templates for high port usage and low disk space using the above to grab the most up to date figures during the recovery alert, and it’s a lot more useful IMHO to see what the port traffic or disk space use actually is after the alerting condition has passed reported by the recovery alert.
One thing I did notice before doing this though is that the figures in $value for recovery alerts were not the original values recorded when the alert first triggered - they are the values recorded in the previous polling period. So if the alert persists for multiple 5 minute polling periods the recovery alert shows values from the previous poll that occurred after the original alert but before the alert condition was resolved.
So the recovery values were often different from the initial alert if the alert lasted more than one polling period and the quantity being measured was varying, but they were still values within the alerting range rather than values outside the alerting range that will be shown now with direct access to the most up to date data.