Hi Community,
I hope you can help with an issue I have encountered.
I have created a new transport in LibreNMS to notify a Xymon server. The transport has its own Template to match the syntax needed to being used with the Xymon client. This has been tested and works fine.
There’s just one issue, namely that the transport is not being called by LibreNMS as regularly as it should be. I wrote a wrapper script to log every time the alert has been triggered and it just happens to sometimes randomly not triggering for some checks. (LibreNMS is set to use 1-Minute-Polling.)
Xymon requires an update on the status at least every 30 minutes, otherwise it changes the state of the check to UNKNOWN (purple color in the screenshot).
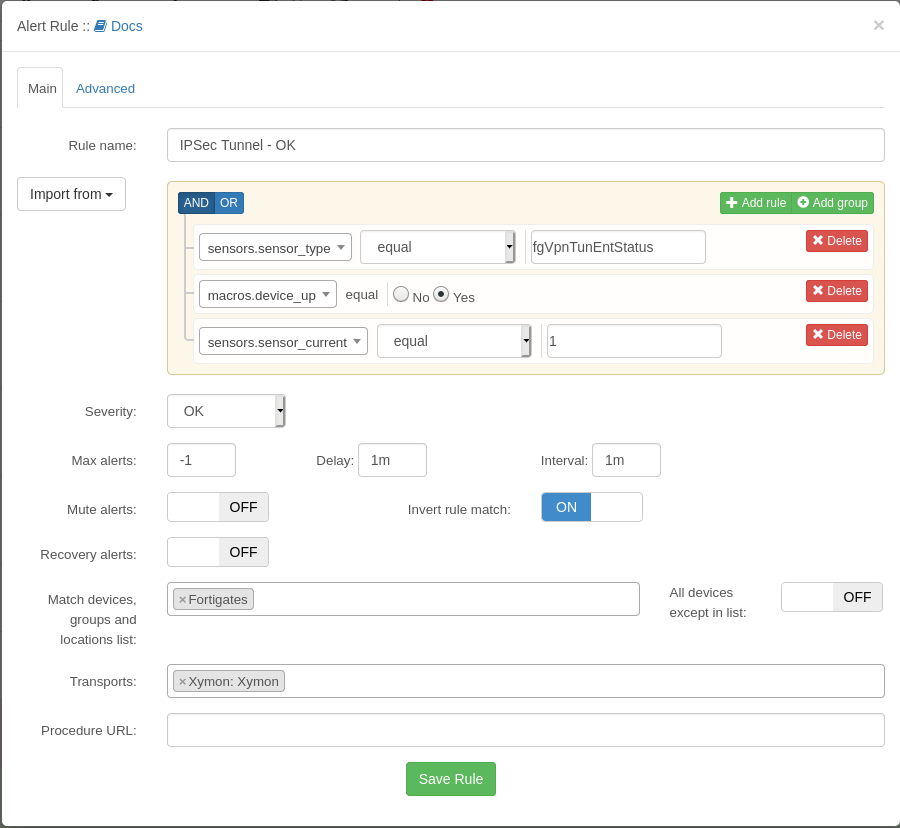
The settings for Critical is the same, just with severity CRITICAL and the sensor not equal 2.
(Could not attach a second screenshot as I am a new user.)
The output of validate.php has been omitted as it does not show anything out of the ordinary.
Does anyone have any idea why LibreNMS does not trigger the Alert regularly as expected?
Thanks in advance!
Hi @Mick
I am not sure to get it. Alerts are for Critical or warning events. And if you don’t have these situations, then you don’t have an alert. Are you trying to create an alert “OK” that would trigger when nothing is wrong, every 1 minute ?
Does the “Critical” alert work well or do you see the same behaviour there ?
Hi @PipoCanaja
I am trying to trigger an OK alert every minute. That’s correct.
The Xymon server is our main monitoring and receives the OK alert from LibreNMS, converting it into the OK state shown on its dashboard. It needs at least one update (no matter if OK or not) every 30 minutes. If it does not receive any update it will change to the UNKNOWN state.
I know that the limit of 1 minute is a very short time period, but the status of those IPSec tunnels is pretty critical
I did not check if this behavior would be the same for CRITICAL/WARNING states in LibreNMS.
But that’s a good idea and I will test this.
Hi everyone!
Now after some more debugging with a colleague we finally found our problem!
We do have two LibreNMS servers in a working distributed poller setup. Polling and communication works fine and after checking our logging we built into the transport, we still didn’t have any clue why the transport was not triggered regularly.
Then we started poking into the PHP code (mroe specific the alerts.php) of LibreNMS and added some things to help us seeing what the code was doing and where it could fail. And that was where we found the Laravel locking mechanism employed for sending alerts. It was telling, that it could not always get a lock and died silently without sending any messages. This was due to the fact that the second node had a cronjob for the alerts.php as well. So both were trying to get a lock and were getting in each others way. After removing this from the second node, alerting started to work as expected.
Sadly there was nothing in the logs or notifications LibreNMS shows if something did go wrong.
Maybe we could update the documentation on “Scaling LibreNMS” to emphasize not to use the alerts.php cronjob? And furthermore I think that such a locking-error would be a nice to know in either the logs or the web UI.
Hi @Mick
Good thing you found the issue. Could you update the documentation (to emphasize the fact that alert.php must run on one master node only) and the code (to make visible in librenms.logs when a lock issue occurs ?
Thanx