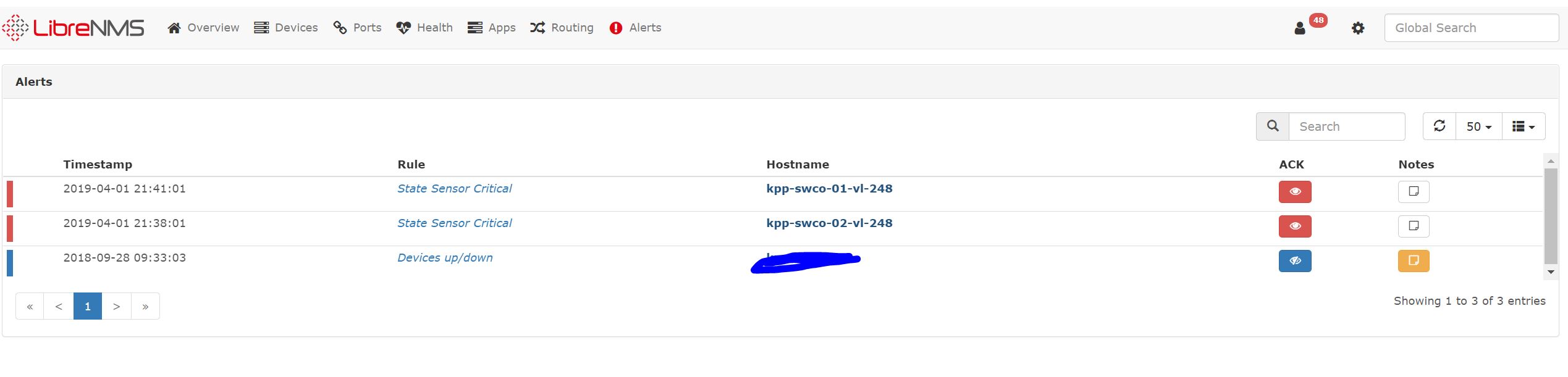
I’ve been receiving alerts beginning overnight for a pair of Cisco WS-C3850-48XS-S: #1: Stack Ring - Redundant;
Current Value: 2 (state)
These alerts started with the 1.50 update and begin once the device has been rediscovered.
The two switches in question have stack ports but they’re not connected or in use, so these alerts are a false alarm.
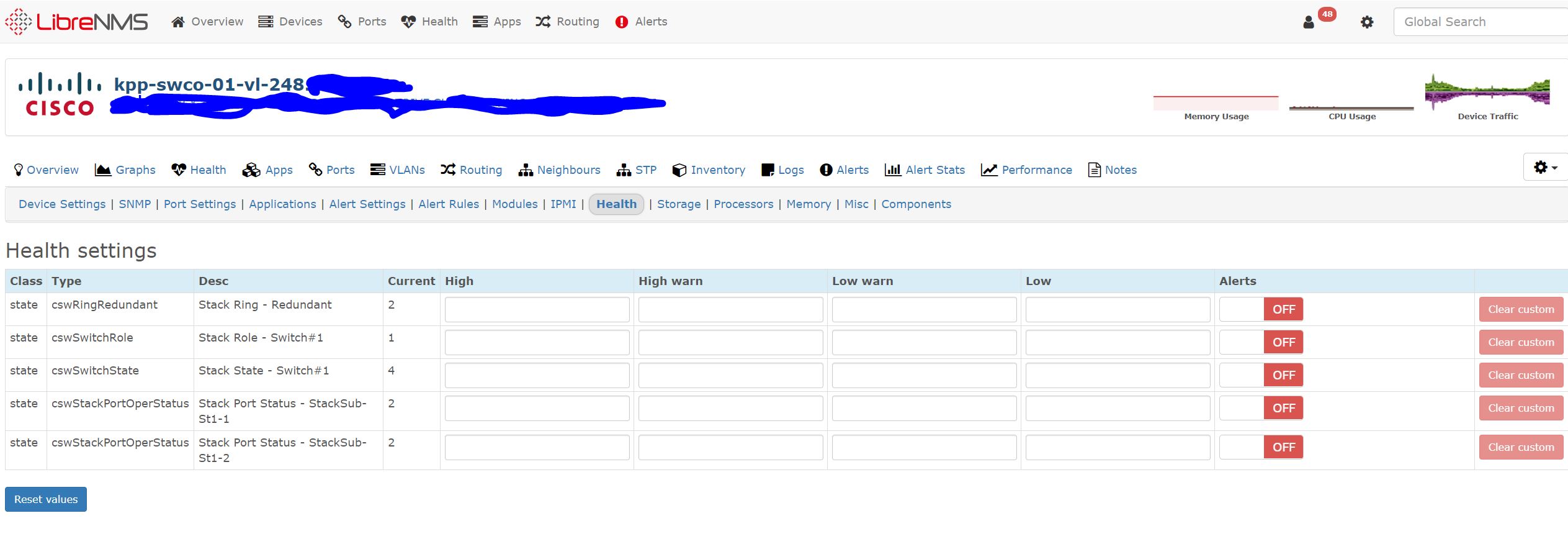
The only settings I can find in the webgui that I think could be related to this are under device, edit, Health. I’ve disabled those health monitors for the stack ports and an hour later they;'re still alerting. I don’t want to just disable alerts because clearly there’s no problem with the device and the alerts aren’t correct.
Interestingly enough, there are also no other health monitors listed for the 3850’s once the rediscovery occurs.
Any suggestions on how to stop the false alarms for this sensor?
Any suggestions on how to get the previous health monitors back in place for these devices?
Interstingly enough, the other device stopped alerting 30-45 minutes after I disabled the new checks that showed up under Edit > Health. For the device that stopped alerting, I’m no longer seeing a Health option under Edit, but that’s not the primary concern at the moment.
bash-4.2$ ./discovery.php -d -m sensors -h [SCRUBBED]
LibreNMS Discovery
SQL[select migration from migrations order by id desc limit 1 [] 0.5ms]
SQL[select count(*) as aggregate from migrations limit 1 [] 0.36ms]
SQL[SELECT version() [] 0.16ms]
===================================
Version info:
Commit SHA: 9661e6b9b36ac1cb1926d8a5910c5997ce59ffe9
Commit Date: 1554090241
DB Schema: 2019_02_10_220000_add_dates_to_fdb (132)
PHP: 7.2.14
MySQL: 5.5.60-MariaDB
RRDTool: 1.4.8
SNMP: NET-SNMP 5.7.2
==================================DEBUG!
Updating os_def.cache…
Done
Override discovery modules: sensors
SQL[SELECT * FROM devices WHERE disabled = 0 AND snmp_disable = 0 AND hostname LIKE ‘[SCRUBBED]’ ORDER BY device_id DESC [] 0.61ms]
The problem hasn’t happened for a couple hours, very strange.
Sorry, I’m not familiar with the different debugging tools. Here’s the proper discovery.php output, along with the validate.php output. When I ran these cmds, the problem was happening for the 3850 switch who’s name was SCRUBBED.
A lot of sensors are failing, no reply from the device (you should check if your SNMP config is correct). The SNMP value should be replied by the device , you can run the snmpbulkwalk commands from your CLI.
May be a device upgrade/downgrade took place recently as well?
1. Timeout: No Response from udp:[SCRUBBED]:161
2. entSensorScaleSNMP['/usr/bin/snmpbulkwalk' '-v2c' '-c' 'COMMUNITY' '-OQUs' '-m' 'CISCO-ENTITY-SENSOR-MIB' '-M' '/opt/librenms/mibs:/opt/librenms/mibs/cisco' 'udp:HOSTNAME:161' 'entSensorScale']
* Timeout: No Response from udp:[SCRUBBED]:161
3. entSensorValueSNMP['/usr/bin/snmpbulkwalk' '-v2c' '-c' 'COMMUNITY' '-OQUs' '-m' 'CISCO-ENTITY-SENSOR-MIB' '-M' '/opt/librenms/mibs:/opt/librenms/mibs/cisco' 'udp:HOSTNAME:161' 'entSensorValue']
* Timeout: No Response from udp:[SCRUBBED]:161
etc etc
Last upgrade to these 3850 switches was ~1 year ago, no recent changes.
This problem started with the 1.50 update. What’s interesting is the devices go into alarm due to these sensors every once in a while. The alarm occurs, and when that happens the sensors appear under Edit > Health and they’re all enabled. I’ll disable them, and within a couple hours or so, the alarms clear, but what actually happens is the sensors under Edit > Health dissapear. Then a couple hours later, they re-appear again. We have several 2960’s in stack configurations that are not having this issue.
I agree, it’s odd that there are no responses, however these 3850’s are healthy, no known issues. Not sure why the update to 1.50 would make this problem occur, but nothing was changed on the 3850’s. I’ve been monitoring them for a year now.
As for the mysqlnd install, this is a new error, we weren’t seeing this a month or so ago. I asked one of our sysadmins to assist, because when I tried to install that using yum I had an error that it wasn’t part of any of the configured repositories. He told me that we have php72w-mysql installed which is the same thing. Dunno?
For the device, we can see that it does not reply correctly to SNMP requests … So until that point is solved, one way or the other, LibreNMS will miss some packets, and if this occurs during discovery, you’ll loose the sensor until next discovery.
However, the problem with the alerts for the stack ports still exists. These alerts never occurred for these two 3850’s prior to v1.50. If you look at the attached screenshots, you’ll see I disable the “heatlh” checks for these sensors, but they continue to alert. Any ideas what could be wrong?
In regards to the no responses… I agree, there are times when there is no response, this is a limitation of the WS-C3850-48XS-S, we’ve been tracking occaisional lack of response to SNMP on these switches for some time. In fact, a case opened with Cisco resulted in TAC telling us that this is a known issue for the WS-C3850-48XS-S platform. While I find that hard to believe, I just haven’t had the time to dig into this too far. This problem with the stack port alerts never occurred prior to 1.50.
Thanks. Where could I have learned that? I had no idea this was an option, I always assumed setting the alerts switch to off was all that was needed.
I’ll assume this started happening in 1.50 only because these stack sensors were recently added and since the 3850 has some SNMP performance related issues, maybe it’s not good for us to monitor these OID’s. It’s ok, we don’t use the stack port functionality on these 3850’s anyhow.
Hi,
There is a sensor alert part of the default templates, that’s probably the easier way you could have identified this.
But there is a dedicated page in the doc : https://docs.librenms.org/Alerting/Macros/
The key you have to know is that all alerting is done based on the database (mysql) so if there is no check on a particular element, then it will just be ignored.
I turn the alerts under Edit > Health > Sensors for these particular sensors off, then at some interval (seems to be inconsistent, perhaps because of the poor WS-C3850-48XS-S SNMP performance) they automatically re-enable. I’d like to disable these particular sensors as opposed to all, if that’s an option. Some guidance here is appreciated.
In fact, because of the poor performance, the discovery fails, and the sensor disappear, I suppose. Then later on, the sensor is rediscovered again, and because it is a new one, it is enabled … You should try different versions of IOS XE on this one, and you’ll possibly get a better one.
Ok, I can understand how that could happen. I’m going to try disabling some of the discovery modules for these two switches, maybe that will help until we can find out from Cisco how to improve the SNMP performance problems the platform has. It’s a wonder we didn’t see this behavior with the sensors on the WS-C3850-48XS-S before LibreNMS 1.5.
Discovery modules will not make much difference if they do not discover anything on this particular switch.
Concerning 1.50, it does not make much difference on cisco devices as far as I can tell, except if you use 802.1X and if NAC module is enabled, then this one is a fairly new one so it may add some load on the discovery and polling.