Why do you care how long discovery takes, it’s designed not to really matter.
Gaps in graphs are usually down to poller taking longer than 5 minutes. That may be down to poor snmp on the end device as well. I’ve not read the thread but have you gone through the performance doc and confirmed what you’ve tuned?
Why do you care how long discovery takes, it’s designed not to really matter.
Because everytime I start the sensors discovery on a host, all polling request for this host are qeued. As soon as the discovery run finishes, all qeued polling requests are processed. The run takes about 40 minutes to complete, the resulting gap in the graphs for this host has the same size.
Gaps in graphs are usually down to poller taking longer than 5 minutes. That may be down to poor snmp on the end device as well. I’ve not read the thread but have you gone through the performance doc and confirmed what you’ve tuned?
Yes I did. I reduced polling and discovery modules per host, installed rrd caching and activated per port polling on several devices. The results are confirmed in this thead.
This sounds like the device itself can’t handle the number of snmp queries. We don’t do a lot in parallel so I don’t think you’ve got any other option other than disable the sensors discovery module. If nothing much changes then it won’t be an issue.
This sounds like the device itself can’t handle the number of snmp queries. We don’t do a lot in parallel so I don’t think you’ve got any other option other than disable the sensors discovery module. If nothing much changes then it won’t be an issue.
This does not affect only this device. It affects almost all of our devices: different series of supermicro servers and different series of juniper switches. It feels wrong that a sensors discovery that asks like 10 sensors takes 8 times longer than the port discovery on a switchstack with over 240 ports (without per port polling).
I didn’t try this out but I guess without the sensors discovery I would not see the temperature of different components on a newly added host? (We didn’t need to deploy a new server since the problems occured) If so this would be bad, because we had some temperature problems in a datacenter and provided them some temperature graphs. This helped a lot to solve this issue.
The given server is a hardware machine, specifically a supermicro 5017C-MTF running on CentOS 7.3. The messages log of server-01 only gives me incoming snmp connections. I didn’t find any other entries for snmp connections there. On my LibreNMS server there is nothing else interesting.
Here the output of ./discovery.php -h server-01 -d -m sensors
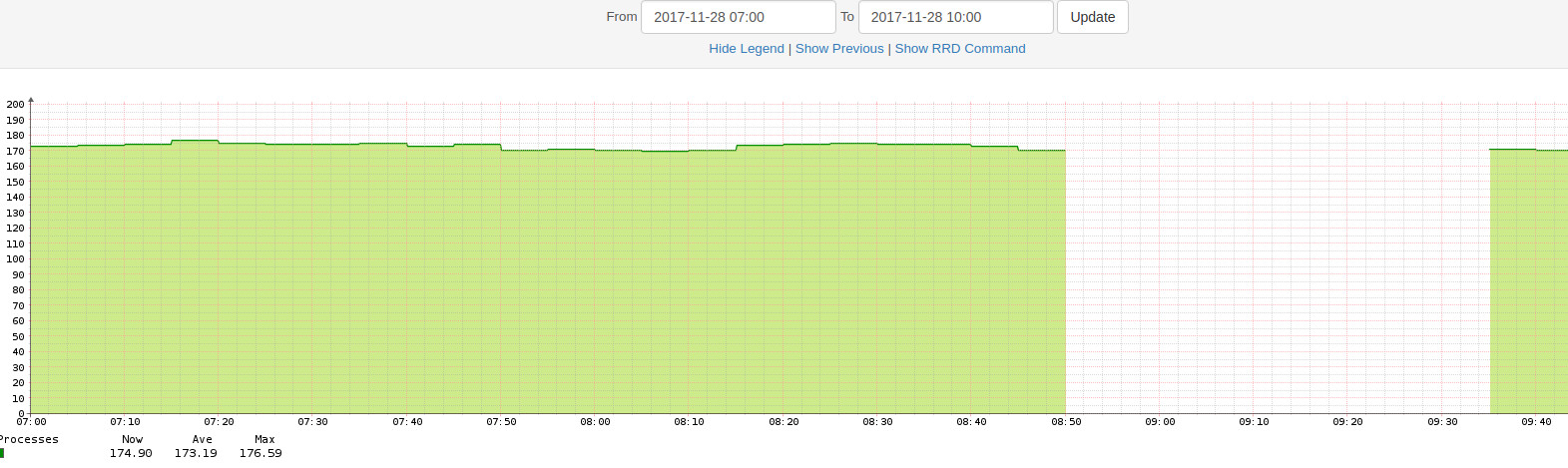
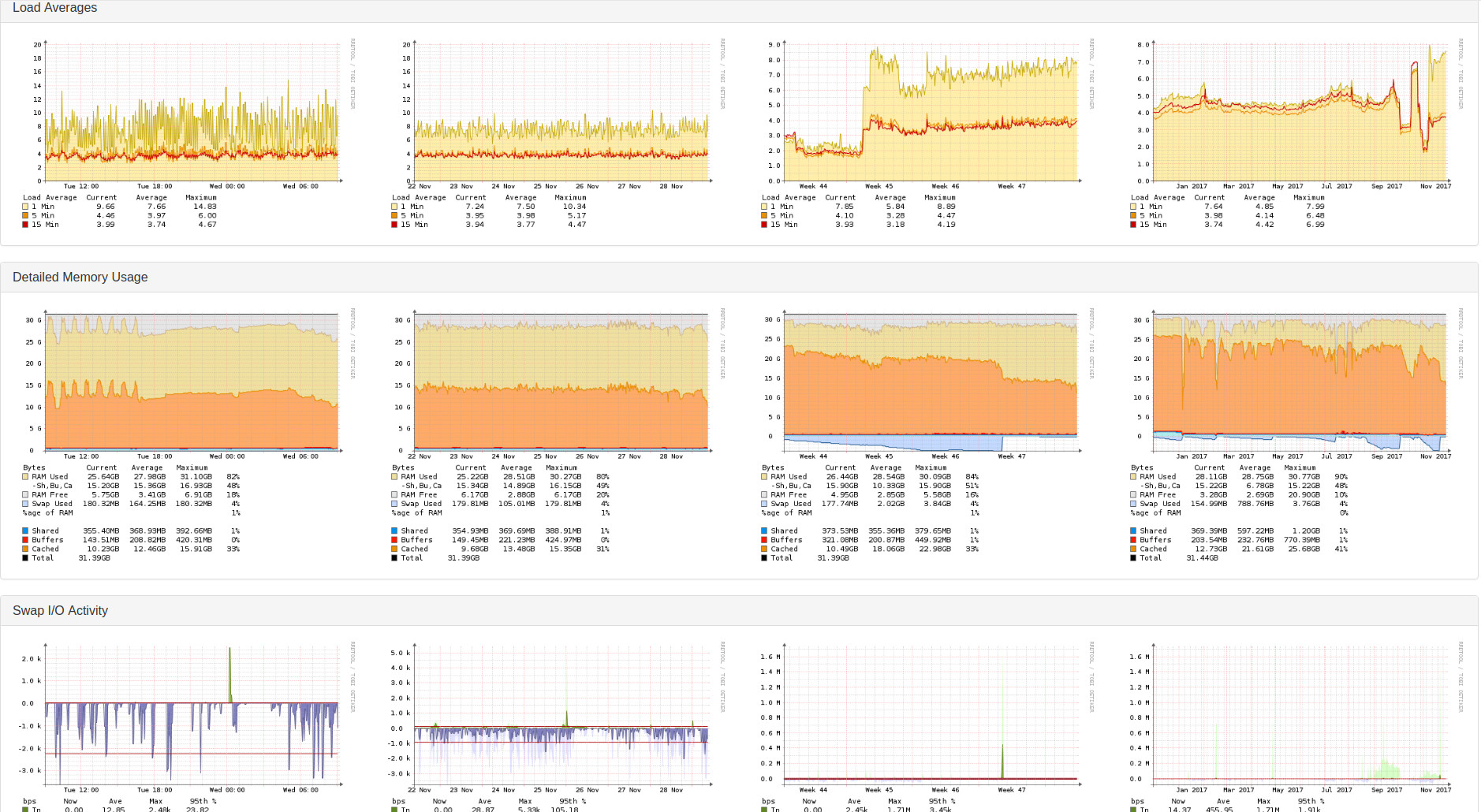
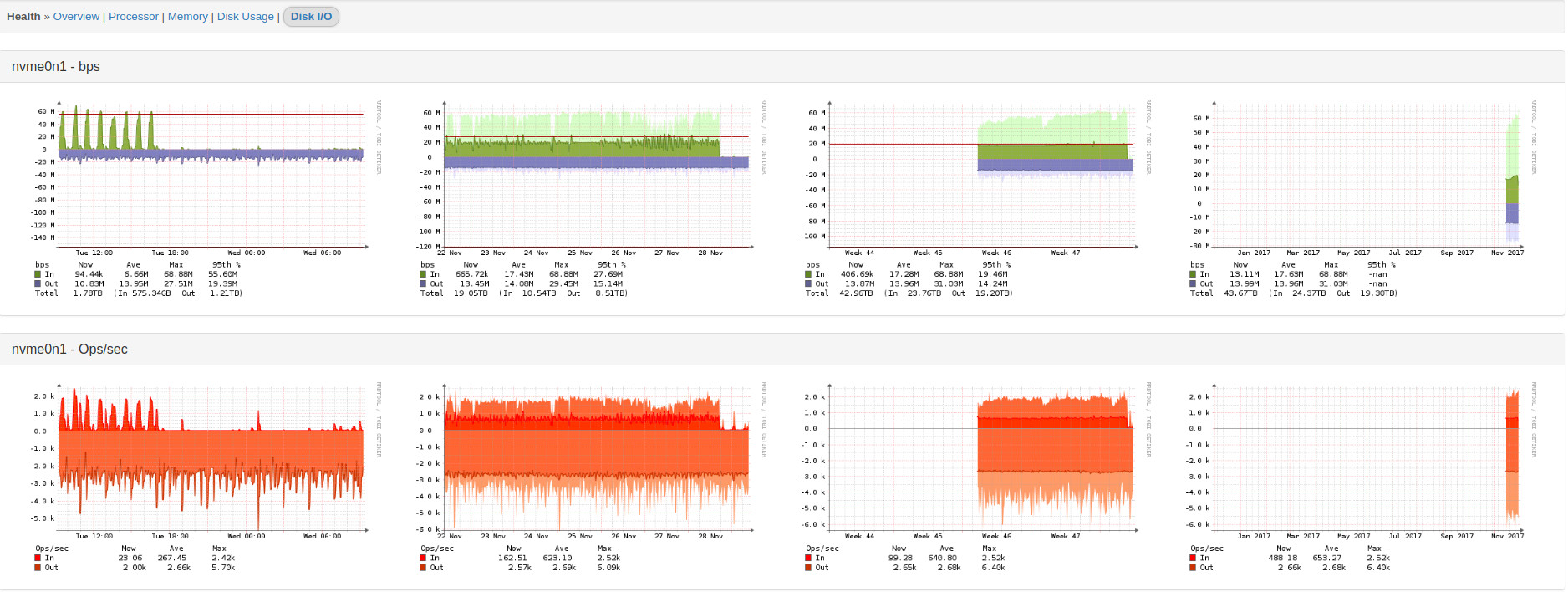
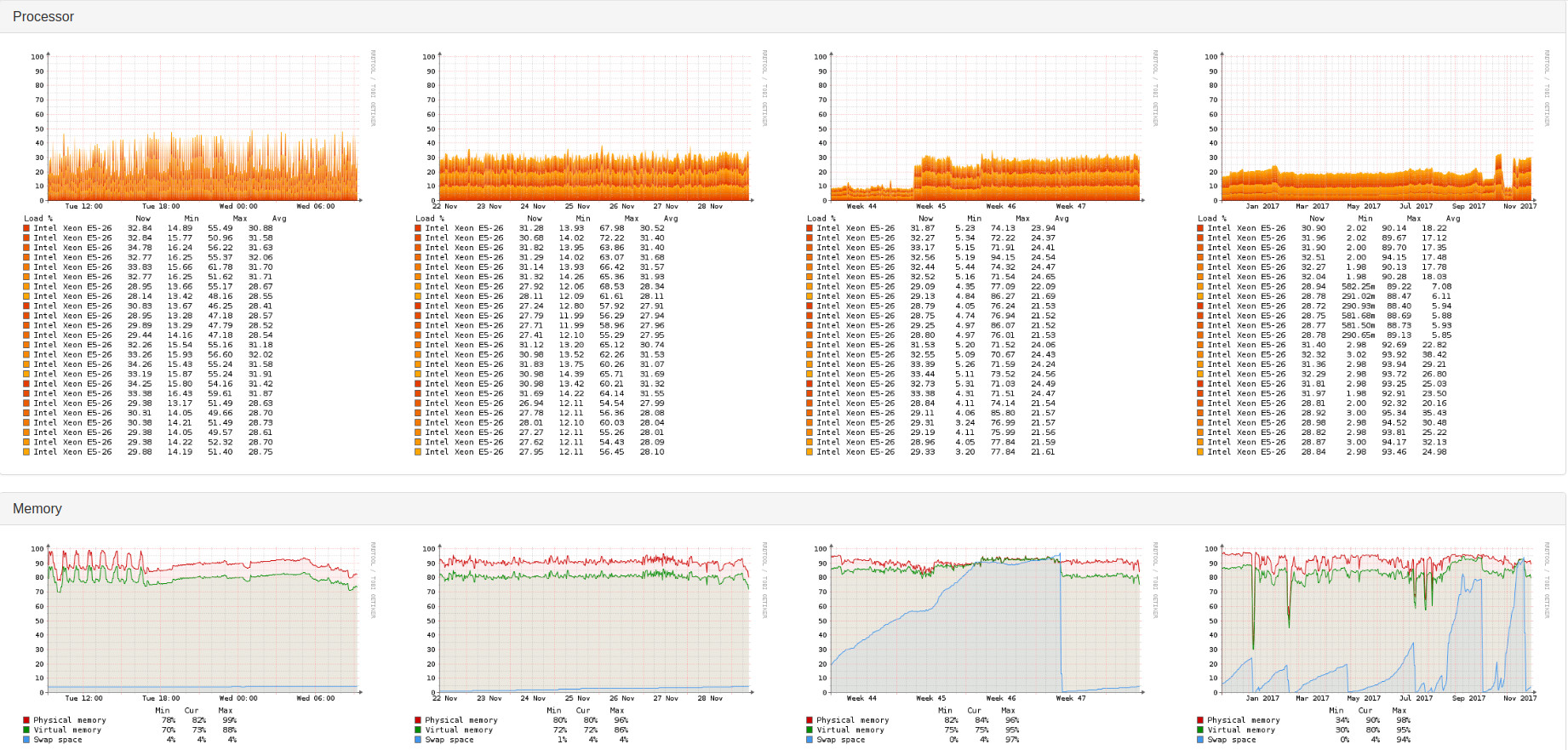
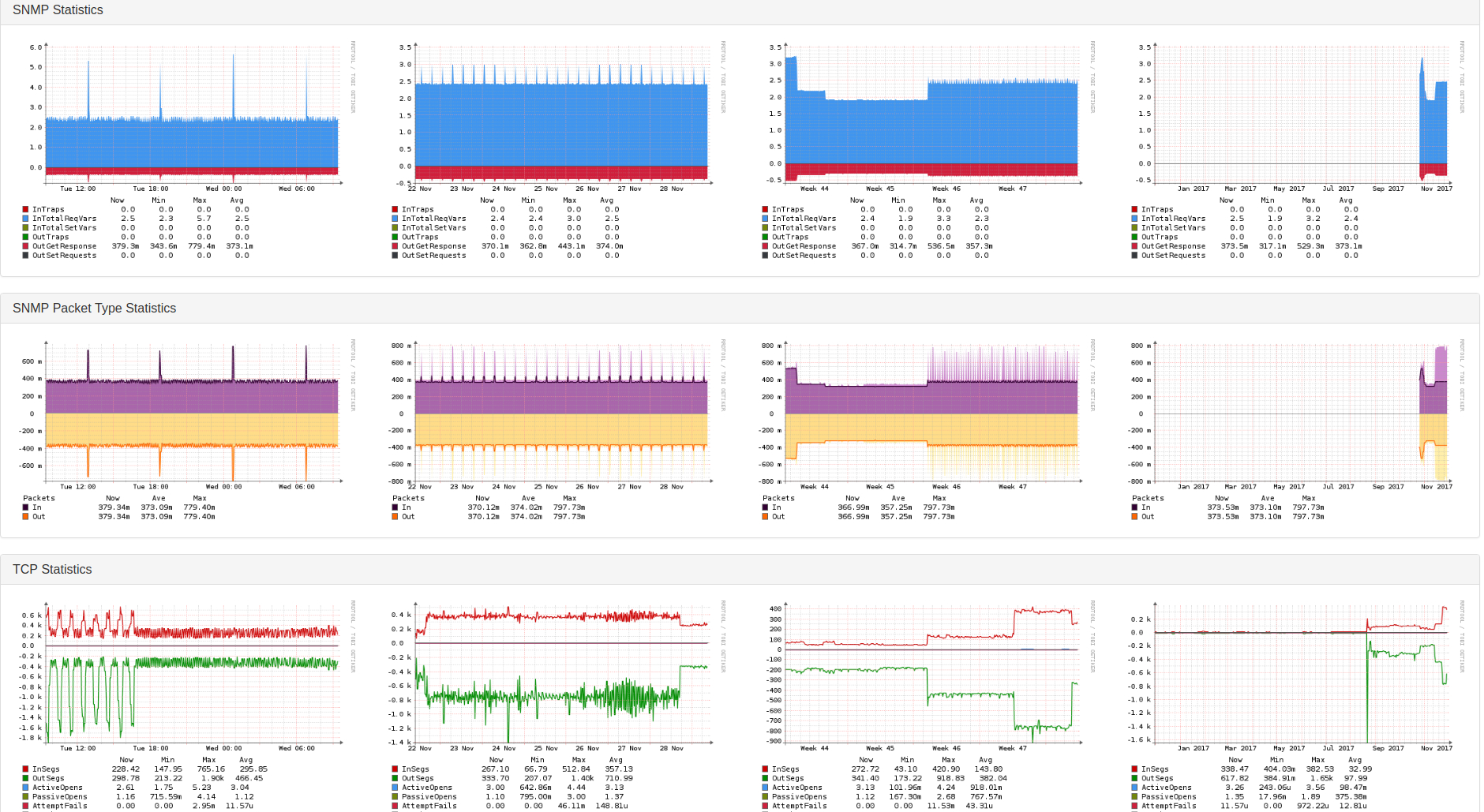
As a proof, in the following the processes graph of server-01:
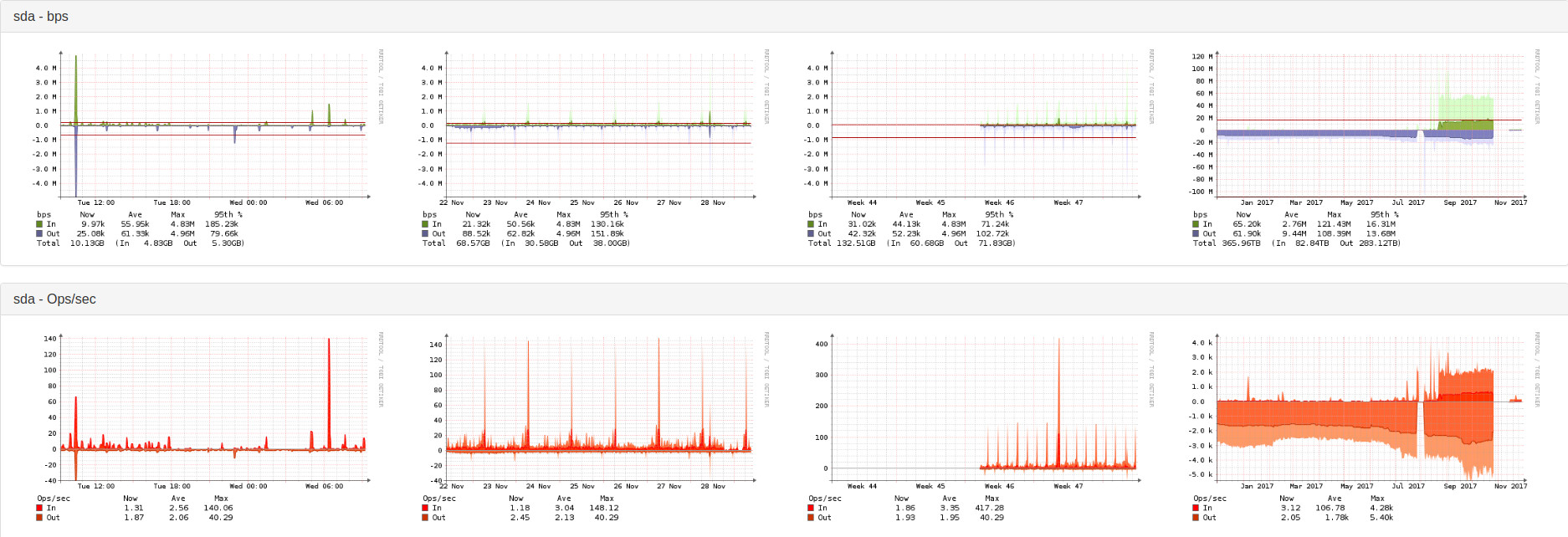
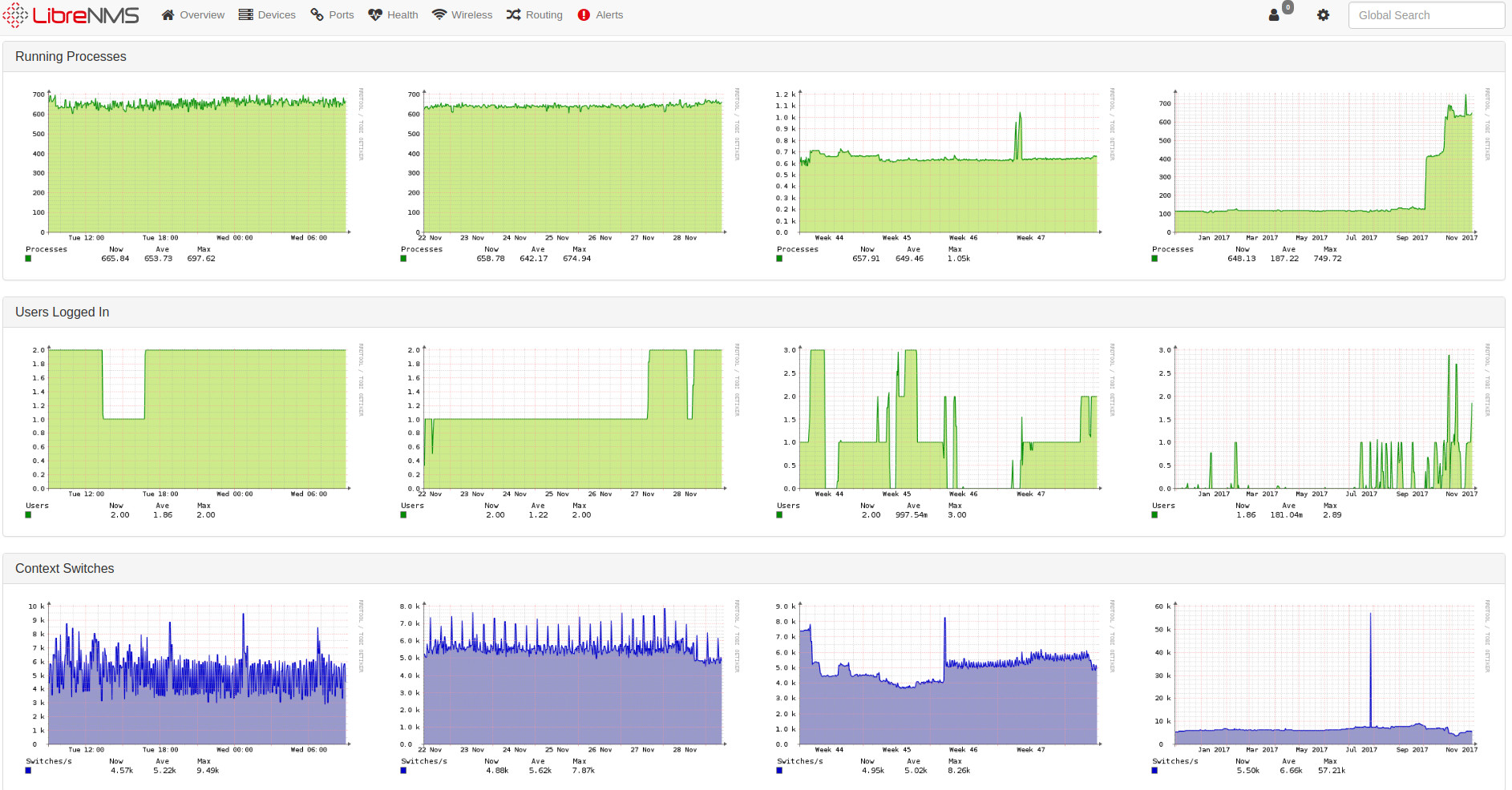
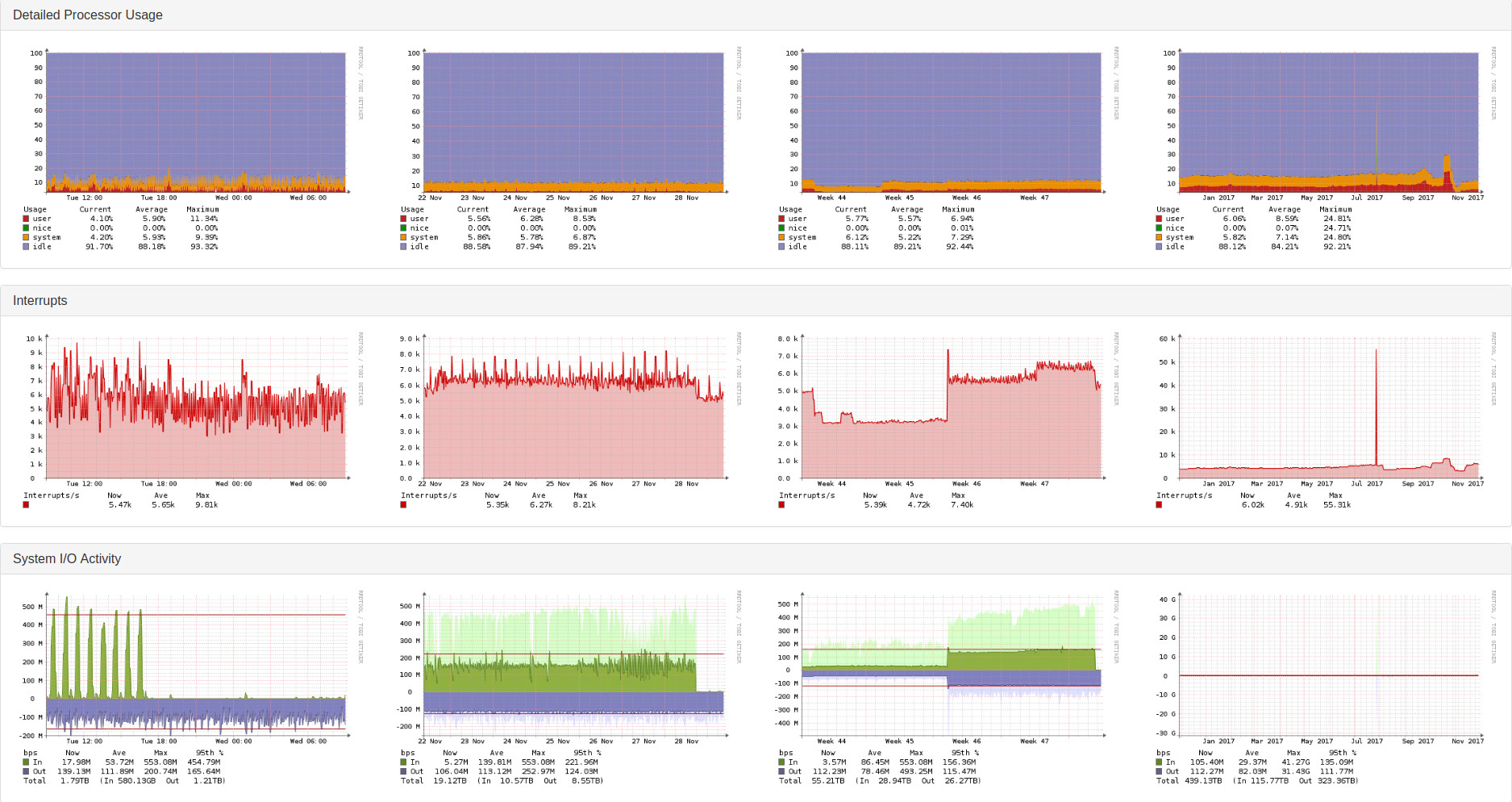
Can you show us the performance graphs from your LibreNMS server such as CPU, Memory, and IO?
Are you using discovery-wrapper.py or just discovery.php?
Below you can find several Graphs of my LibreNMS server. The every 6 hours discovery is running via discovery-wrapper.py. The testing with the sensors modul I do directly using discovery.php.
Looks fine, but I noticed there are not any gaps in those graphs.
Perhaps this is just a bugged device that doesn’t like too many snmp queries at the same time?
There are no gaps because there is no sensors discovery on any host. I have disabled this module globally because of the gaps.
The results I provided were from manually called commands for a host which is dedicated for testing. When the sensors module was enabled globally there were gaps in graphs of almost every machine. Meaning like 15 different server series and various switches.
In my opinion there is a problem with the sensors discovery module itself, because the discovery itself is fine. I mean before I reduced the discovery modules for hostgroups all default enabled modules were queried. As soon as I disabled the sensors module, the discovery went fine. I just disabled uneeded modules to improve discovery time. So, all in all I can successfully query 21 modules on discovery. But doing a discovery run only with the sensors module kills everything?
When I take a look at the given output of the discovery run yesterday, I’m a bit puzzled:
Why is the precache for Linux Raspberry Pi?
Is there a way that I can reduce “/opt/librenms/mibs:/opt/librenms/mibs/supermicro:/opt/librenms/mibs/dell” only to “/opt/librenms/mibs/supermicro”? This would maybe reduce the snmp queries? In addition we’re only running supermicro machines right now.
Discovery time is not that important, it does not block polling. I looked at your discovery log, the sensors module took ~2703 seconds, of that about 2700 seconds were waiting for snmp responses until the timeout.
Linux is extremely generic and has to check for many things, we do this in the discovery so we can optimize poller performance where time is important.
Because it runs Linux
Reducing the mib directories will not do anything except cause some mib oid lookups to fail.
We need more information on what is going on, because it feels like you are looking in the wrong direction and we don’t know enough to figure it out. Unfortunately, I’m not really sure what information we need.
Almost every machine
is an important distinction from every machine.
I switched to almost, because I didn’t check every of our almost 700 servers. When this problem occured I was told about 50 servers which had gaps and every machine I looked at during this time had gaps in their graphs. So let’s say I confirmed around 100 different machines with gaps in graphs.
Discovery time is not that important, it does not block polling. I looked at your discovery log, the sensors module took ~2703 seconds, of that about 2700 seconds were waiting for snmp responses until the timeout.
Yes I saw this too. That’s why I thought about reducing the snmp queries. Because there is this arbitrary Pre cache raspberry pi query which times out. Then there are those cisco queries which of course time out too, because it’s a supermicro server. After the timeout of the entity sensors which don’t exist too, it runs smooth.
It would be nice if I could state: these 100 machines are supermicro servers, only look for the supermicro sensors on them (“/opt/librenms/mibs/supermicro”). At least that’s what I think, I don’t know what happens exactly behind the curtain.
If you run discovery on one device, does it cause gaps in other devices, or only that device?
When I run the sensors discovery on one host, only this host has gaps in his graphs. But I can’t tell you for sure that there were not any side effect due to the many snmp queries in queue on my LibreNMS host when the sensors module was enabled globally.
We need more information on what is going on, because it feels like you are looking in the wrong direction and we don’t know enough to figure it out. Unfortunately, I’m not really sure what information we need.
I’ll try to provide more detailed information from both sides.
This is definitely a concern: ./poller.php server-01 2017-12-01 12:18:05 - 1 devices polled in 1289. secs
What’s weird is the module stats don’t show where this time is taken so it could be in the initial snmp gets we do. However the output does show your install is out of date, please update your install. I’ve also just checked your commit you are running and it’s not one of ours so you have some local modifications. Please go back to the master branch and try again.
What’s weird is the module stats don’t show where this time is taken so it could be in the initial snmp gets we do. However the output does show your install is out of date, please update your install.
By the end of this week or beginning of next week I’m going to update my LibreNMS. Right now I don’t have time for this at work.
I’ve also just checked your commit you are running and it’s not one of ours so you have some local modifications. Please go back to the master branch and try again.
So, I was quite busy the last days, but I made it to figure some things out.
First of all I made a fresh LibreNMS clone from state of 2017.12.07 and adjusted only the .htaccess to make the api work with fpm.
Today I tried a sensors discovery run on 4 different machines:
Supermicro 5017C-MTF, Debian 8
Supermicro 5018D-MTF, Debian 8
Supermicro 6017R-WRF, Centos 7.4
Supermicro 5019S-WR, Debian 7
You can find the output (which iwas identical for each server) until I canceled the run manually, below:
Summary
./discovery.php -d -h server-foo -m sensors
LibreNMS Discovery
===================================
Version info:
Commit SHA: a8ca43b991f986f6fe317b7e161e85778bf0cdcc
Commit Date: 1512650800
DB Schema: 222
PHP: 7.0.19-1
MySQL: 10.1.26-MariaDB-0+deb9u1
RRDTool: 1.6.0
SNMP: NET-SNMP 5.7.3
==================================DEBUG!
SQL[SELECT * FROM `devices` WHERE disabled = 0 AND snmp_disable = 0 AND `hostname` LIKE 'server-foo' ORDER BY device_id DESC]
SQL[SELECT * FROM devices_attribs WHERE `device_id` = '568']
server-foo 568 linux SQL[INSERT INTO `device_perf` (`xmt`,`rcv`,`loss`,`min`,`max`,`avg`,`device_id`,`timestamp`) VALUES ('3','3','0','0.18','0.24','0.20','568',NOW())]
SNMP Check response code: 0
SQL[SELECT attrib_value FROM devices_attribs WHERE `device_id` = '568' AND `attrib_type` = 'poll_mib' ]
Modules status: Global+ OS+ Device
#### Load disco module sensors ####
Pre-cache linux: RaspberryPi SNMP[/usr/bin/snmpbulkwalk -v2c -c COMMUNITY -OQUs -M /opt/librenms/mibs:/opt/librenms/mibs/supermicro:/opt/librenms/mibs/dell -t 60 -r 10 udp:HOSTNAME:161 .1.3.6.1.4.1.8072.1.3.2.4.1.2.9.114.97.115.112.98.101.114.114.121]
I canceled the run manually after 5 minutes, because I wanted to avoid gaps in graphs for these production servers. But this didn’t work out. All four produced gaps. The servers 1 and 2 were even marked down by snmp in those 5 minutes and this produced a 45 minute gap for each server until they were marked back up again.
So i actually have no clue what to try or to do further here.