Even though there is a mdadm application available that somewhat pull mdadm information it does not seem to correctly set the “degraded” state if there are multiple mdadm arrays.
====================================
Component | Version
--------- | -------
LibreNMS | 1.61-85-gd4aa45039
DB Schema | 2020_03_24_0844_add_primary_key_to_device_graphs (160)
PHP | 7.4.3
MySQL | 10.1.44-MariaDB-0ubuntu0.18.04.1
RRDTool | 1.7.0
SNMP | NET-SNMP 5.7.3
====================================
Device ID is 28
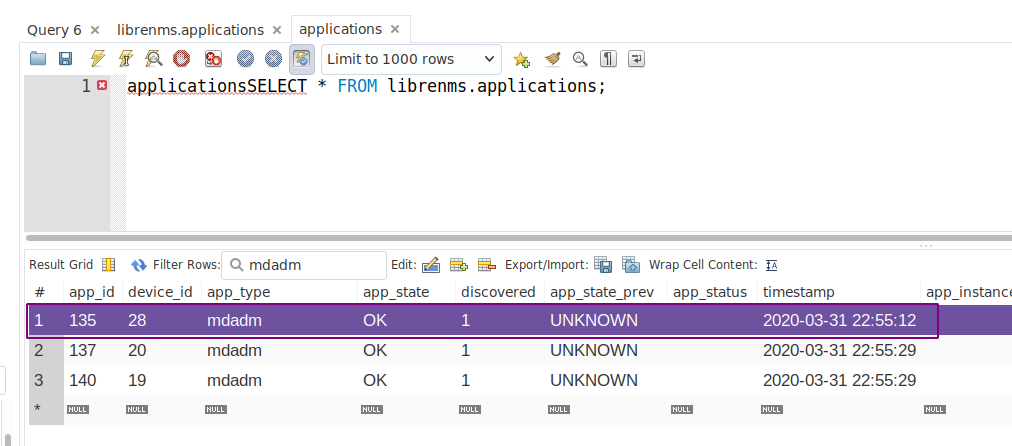
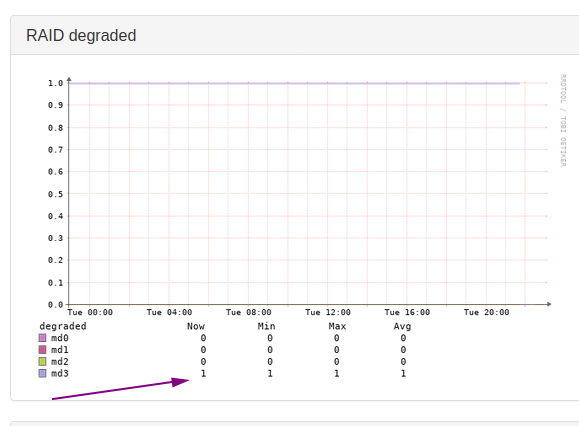
I cannot fix this myself, not a programmer but would be very happy if this was fixed soon. Raids failed multiple times and no alerts were triggered because of no changes to the db entries.