Hello,
Is anyone monitoring MD RAID through LibreNMS? Specifically, I want to know if a drive has failed. I don’t believe it’s a feature right now but I’m trying to avoid implementing a second monitoring system or some host-specific scripts for this outlier.
So far, I’ve been able to expose RAID status through SNMP using OpenNMS’s guide here:
https://github.com/opennms-config-modules/snmp-swraid
Snmpwalk output example is included here. In short, this is an example with a drive that’s virtually (it’s a VM for testing) failed.:
SWRAID-MIB::swRaidIndex.1 = INTEGER: 1
SWRAID-MIB::swRaidDevice.1 = STRING: md0
SWRAID-MIB::swRaidPersonality.1 = STRING: raid5
SWRAID-MIB::swRaidUnits.1 = STRING: sde4 sdd[3] sdc[1] sdb[0]
SWRAID-MIB::swRaidUnitCount.1 = INTEGER: 4
SWRAID-MIB::swRaidStatus.1 = INTEGER: faulty(3)
SWRAID-MIB::swRaidErrorFlag.0 = INTEGER: 1
SWRAID-MIB::swRaidErrMessage.0 = STRING: Failed RAID devices: md0
However, I can’t figure out if there’s a way to make alerts / triggers with this output in Libre. Any thoughts or suggestiongs? Thanks in advance!
Some extra info:
$ uname -a
Linux hostnameommited 3.10.0-862.3.3.el7.x86_64 #1 SMP Fri Jun 15 04:15:27 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
$ yum list installed | grep mdadm
mdadm.x86_64 4.0-13.el7 @base
$ yum list installed | grep net-snmp
net-snmp.x86_64 1:5.7.2-33.el7_5.2 @updates
net-snmp-agent-libs.x86_64 1:5.7.2-33.el7_5.2 @updates
net-snmp-devel.x86_64 1:5.7.2-33.el7_5.2 @updates
net-snmp-libs.x86_64 1:5.7.2-33.el7_5.2 @updates
net-snmp-utils.x86_64 1:5.7.2-33.el7_5.2 @updates
This is my first post. Please let me know if I’m breaking any etiquette.
I have a new implementation of LibreNMS and am very please switching from the community edition of Observium. Validate output is included below. But, I don’t think it’s relevant to this request.
# /opt/librenms/validate.php
====================================
Component | Version
--------- | -------
LibreNMS | 1.41-2-ge66b5ec
DB Schema | 253
PHP | 7.2.6
MySQL | 5.5.56-MariaDB
RRDTool | 1.4.8
SNMP | NET-SNMP 5.7.2
====================================
[OK] Composer Version: 1.6.5
[OK] Dependencies up-to-date.
[OK] Database connection successful
[OK] Database schema correct
Support for that has be to be added you can add it or make request and see if anybody wants to add code for it.
https://docs.librenms.org/#Developing/Support-New-OS/
Thanks Kevin! I’m happy to make a request for a new feature but would appreciate some guidance. I don’t want to over-tailor it to the methods I’ve tried.
As someone more familiar with the project, should this be a request of the unix agent? SNMP through a specific MIB? Etc…
Even though there is a mdadm application available that somewhat pull mdadm information it does not seem to correctly set the “degraded” state if there are multiple mdadm arrays.
====================================
Component | Version
--------- | -------
LibreNMS | 1.61-85-gd4aa45039
DB Schema | 2020_03_24_0844_add_primary_key_to_device_graphs (160)
PHP | 7.4.3
MySQL | 10.1.44-MariaDB-0ubuntu0.18.04.1
RRDTool | 1.7.0
SNMP | NET-SNMP 5.7.3
====================================
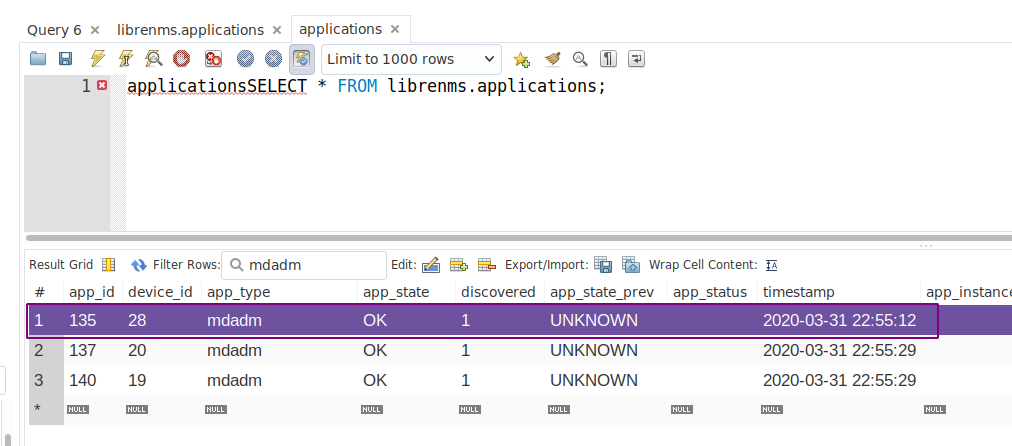
Device ID is 28
I cannot fix this myself, not a programmer but would be very happy if this was fixed soon. Raids failed multiple times and no alerts were triggered because of no changes to the db entries.
What says state of arrays if you type in command line
cat /proc/mdstat
?
App state has nothing to do with the health of your arrays. It hast to do with the state of the application. Running data, including array degraded state are listed in application metric table.
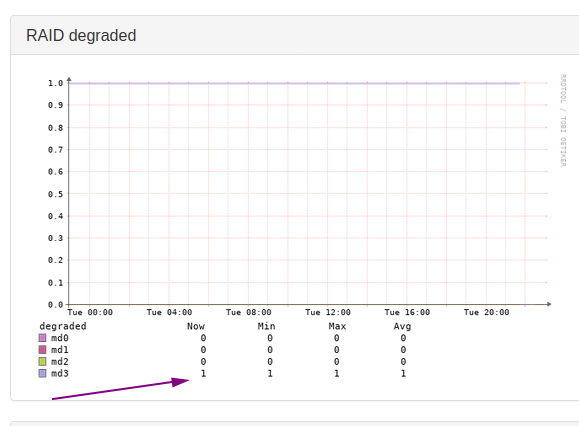
Obviously the mdstat states that the array is degraded. Why else would I write this post? 
But here you go:
root@server:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md1 : active raid1 sda2[0] sdb2[1]
107356160 blocks super 1.2 [2/2] [UU]
bitmap: 1/1 pages [4KB], 65536KB chunk
md0 : active raid1 sda1[0] sdb1[1]
1950720 blocks super 1.2 [2/2] [UU]
md2 : active raid1 sda3[0] sdb3[1]
11710464 blocks super 1.2 [2/2] [UU]
md3 : active raid1 sdc1[2]
463833088 blocks super 1.2 [2/1] [U_]
bitmap: 2/4 pages [8KB], 65536KB chunk
unused devices: <none>
It is nice to have metrics of the mdadm but not really useful if one requires alerts on mdadm failure.
MDADM alerts mails send by the system itself are not enough and there is guarantee that they will be read in time. Therefore a monitoring alert is required.
If the app state is not the one to use for alerts what else to use then to trigger an alert if the array is degraded? What is the app state good for then? Shouldn’t it trigger “NOT OK” or something like that?
if you’d like to have an Alert via monitoring on degraded Array you have to write on.
my Ruleset looks like this:
application_metrics.metric LIKE '%_degraded' AND application_metrics.value = 1
Also i wrote me an Alert Template for degraded Array which looks like this:
{{ $alert->title }}
Severity: {{ $alert->severity }}
@if ($alert->state == 0)
Time elapsed: {{ $alert->elapsed }}
@endif
Timestamp: {{ $alert->timestamp }}
Unique-ID: {{ $alert->uid }}
Rule: @if ($alert->name) {{ $alert->name }} @else {{ $alert->rule }} @endif
@if ($alert->faults)
Faults:
@foreach ($alert->faults as $key => $value)
Array: @php echo (explode("_", $value[‘metric’])[0]); @endphp
@endforeach
@endif
“app state” show’s the health state of Agent and Application itself. As told before you’re searching in a completely wrong table. Application data, are stored in table application_metrics.
Thank you very much for you help. Even though that I am using LibreNMS since a few years I just started looking recently into alerting and plugins/extensions since it became more relevant.
I didn’t know that I can pull metrics for alerting. Thank you!!
There are quiet a few templates for common cases missing in the alert collection library. It would also be nice if there were a bunch of decent alert templates which delivery a readable alert.
The default just pushes way to much information and one has to search and spend a lot of time developing readable templates whereas many people might have this problem. At least for the most common cases there could readable templates.
Is there a project that encourages this somewhere that we could push or even give some input for template ideas?
the problem on templates is
their design often depends on the used Alert Transports
also Alerts often depends on individual handling.
The Alert Collection will be enhanced more and more, but it depends time and someone who is doing it.
@SourceDoctor This doesn’t seem to work. The output doesn’t contain the actual array that is degraded.
The alert output of librenms shows #1: md3_degraded => 1.
I couldn’t figure out how to solve this using the manual. Any idea ?’
Thanks!
this here is exaclty my RUNNING Alert Template, do get defgraded arrays with it’s name:
Severity: {{ $alert->severity }}
@if ($alert->state == 0)
Time elapsed: {{ $alert->elapsed }}
@endif
Timestamp: {{ $alert->timestamp }}
Unique-ID: {{ $alert->uid }}
Rule: @if ($alert->name) {{ $alert->name }} @else {{ $alert->rule }} @endif
@if ($alert->faults)
Faults:
@foreach ($alert->faults as $key => $value)
Array: @php echo (explode("_", $value['metric'])[0]); @endphp
@endforeach
@endif
1 Like
Thanks. I will check again for syntax errors in the template. Is it maybe because I am using markdown in my templates?