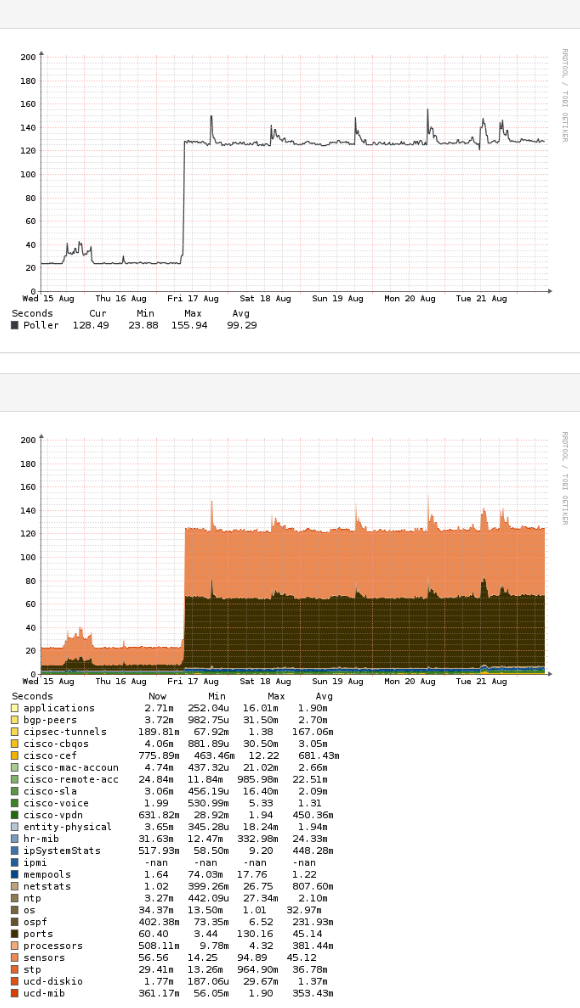
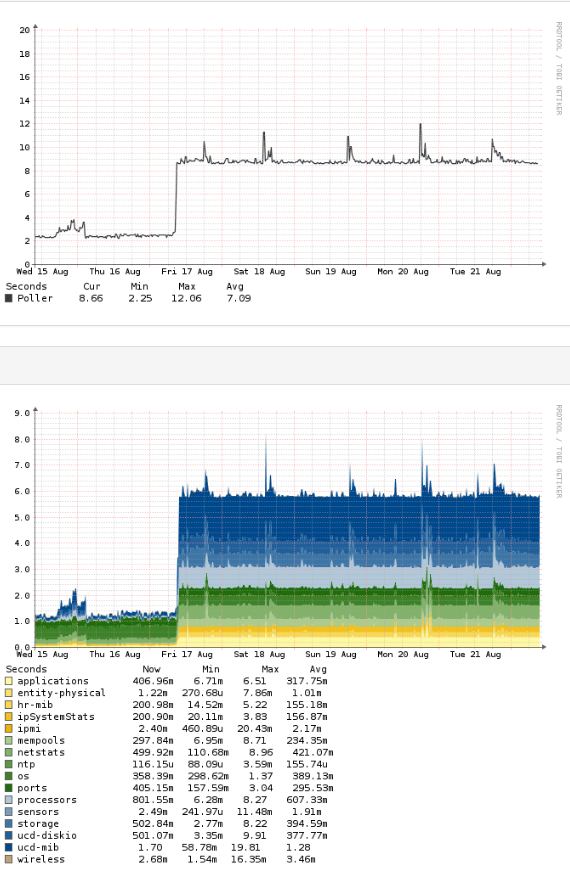
RRDcache on, local dns rekursor, pDNS etc. all was setup and I got the polling time down from 300s with defautl settings down to ~40s on one device with all devices polling less then that.
[OK] Composer Version: 1.7.2
[OK] Dependencies up-to-date.
[OK] Database connection successful
[OK] Database schema correct
[FAIL] Some devices have not completed their polling run in 5 minutes, this will create gaps in data.
[FIX] Check your poll log and see: Performance - LibreNMS Docs
Devices:
[FAIL] We have found some files that are owned by a different user than librenms, this will stop you updating automatically and / or rrd files being updated causing graphs to fail.
[FIX] chown -R librenms:librenms /opt/librenms
Files:
/opt/librenms/html/plugins/Weathermap/configs/location-example.php
/opt/librenms/html/plugins/Weathermap/configs/aistest.php
/opt/librenms/html/plugins/Weathermap/configs/AIS DC.php
/opt/librenms/html/plugins/Weathermap/configs/group-example.php
/opt/librenms/html/plugins/Weathermap/configs/testmap.conf
/opt/librenms/html/plugins/Weathermap/configs/hostname-example.php
/opt/librenms/html/plugins/Weathermap/configs/home-network-example.php
weathermap has www-data as owner.
Try ./poller.php -d -h host -m ports or -m sensors, as are the ones with biggest polling times. Then you can check what is taking so much time, if SNMP, MYSQL or RRD.
I bet is a disk issue. Whats your disk I/O for librenms?
Running the poller there is no obvious hold up or wait times, the script is running along printing output/results continuously.
Although there’s alot of output writing to influxdb , but that has been running flawless for month.
Im gonna try and turn off influxdb and see.
Wee need influxdb tho, for our Grafana dashboards.
another observation, I have no apparent discontinuous graphs (running 1min polling) and with some polling taking 140s I should have gotten blanks in the RRD graphs.
We are currently seeing the same issue with our LibreNMS deployment. We are seeing a notification when when logging into the portal which says: ‘It appears as though you have some devices that haven’t completed polling within the last 15 minutes, you may want to check that out :)’. Upon further investigation we have identified that 4 of our LNS routers are having issues with polling timeouts. From the poller graphs, it seems to be a timing out issue revolving around the OS/Ports. I have run snmpwalk on one of the affected devices and this is pulling data back.