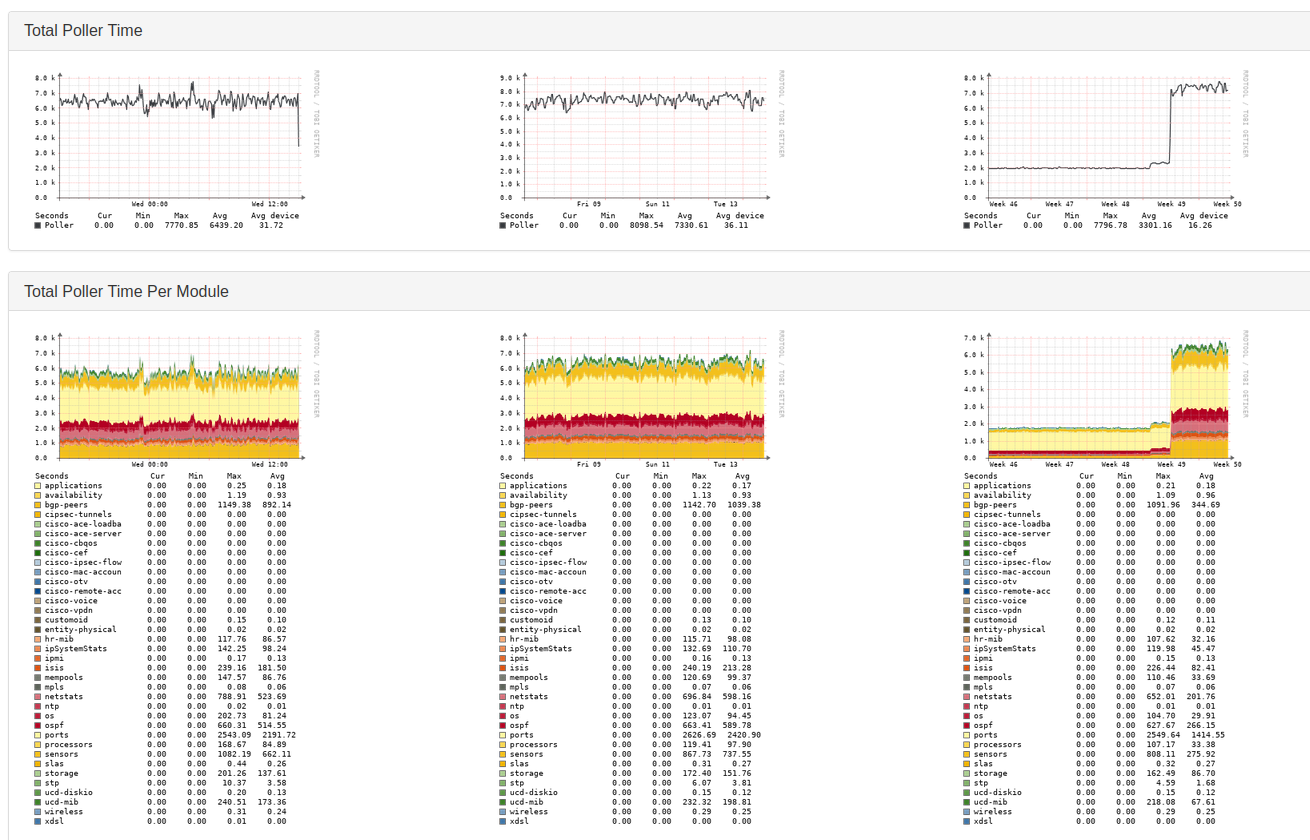
Hello all. I have two separate instances of LibreNMS both which are experiencing dramatically higher polling times since a daily update. I am posting this about a week after the initial impact. As of Wednesday, 12/07/22, between 8:35 AM and 8:45 AM CST, total poller time increased on one instance from 2.0k to 7.5k. This has caused devices to not be able to complete polling in the 5 minute interval which is causing significant gaps in port graphs.
The second instance seems to have run it’s daily update at a different time but afterward demonstrates a similar increase in polling times. It has fewer devices being polled so is less impacted, but the poller performance is noticeably poorer.
Neither instance is distributed. Database, web, rrdcached, and polling all in a single VM. I do not see any significant resource contraint on either VM. Debug/capture polling shows strange results. I do get “normal” response times from high-impact devices sometimes but other times get high polling times in debug mode. This seems to reflect the issue as specific device polling times are quite variable since the onset of this issue.
Primary LibreNMS instance validate.php output is below:
$ ./validate.php
| Component | Version |
|---|---|
| LibreNMS | 22.11.0-21-g47cc169 (2022-12-12T02:02:49-06:00) |
| DB Schema | 2022_08_15_084507_add_rrd_type_to_wireless_sensors_table (248) |
| PHP | 8.2.0RC7 |
| Python | 3.6.8 |
| Database | MariaDB 10.5.18-MariaDB |
| RRDTool | 1.4.8 |
| SNMP | 5.7.2 |
| =========================================== |
[OK] Composer Version: 2.4.4
[OK] Dependencies up-to-date.
[OK] Database connection successful
[OK] Database Schema is current
[OK] SQL Server meets minimum requirements
[OK] lower_case_table_names is enabled
[OK] MySQL engine is optimal
[OK]
[OK] Database schema correct
[OK] MySQl and PHP time match
[OK] Active pollers found
[OK] Dispatcher Service not detected
[OK] Locks are functional
[OK] Python poller wrapper is polling
[OK] Redis is unavailable
[OK] rrd_dir is writable
[OK] rrdtool version ok
I don’t see anything significant in logs except evidence of the higher polling times after the given datetime above. I’m struggling to find evidence of when exactly the software might have been updated. Is there an easy way to determine this?
I’ve found some buzz in previous years about configuring the dispatcher service so will look into that further. Just seems odd that these two instances have worked without a hitch for a couple of years and in one instant performance dropped dramatically. Anyone have any insight or further troubleshooting steps I should take?