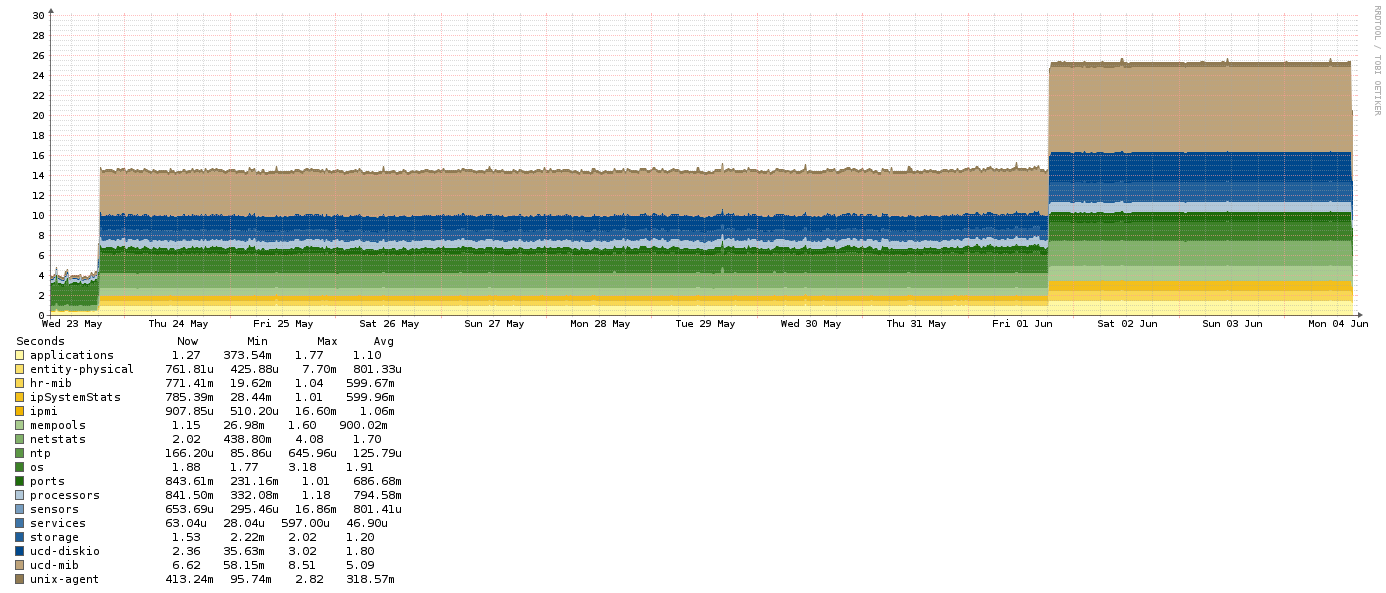
Prior to May 23rd, I was exporting metric to InfluxDB with no apparent performance penalty. Between May 23rd and 24th, my polling times suddenly got extremely high:
You can see the spike on May 23rd, and then another spike on June 1st. I made no changes on either of these days.
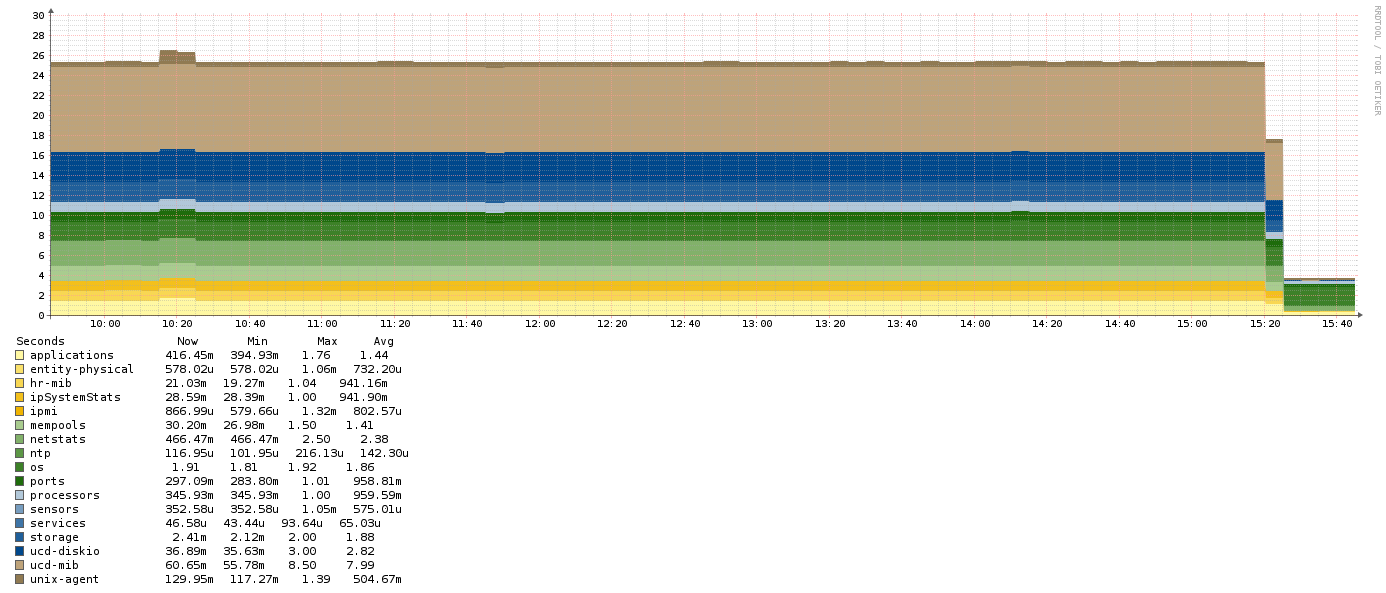
On June 4th I disabled the connection to InfluxDB and poller times dropped back to normal:
Running the poller with full debug output showed that the poller is pushing each metric to Influx as it polls instead of batching them up by host. I don’t have debug output from before things apparently went wrong so I can’t say how the poller was interacting with Influx before these two instances. The host shown in both graphs is a very basic Linux box, using SNMP and the agent to monitor the basic system stats (CPU, memory, disk), as well as Apache, MySQL, and the NTP Client. My config was using HTTP to submit the metrics to Influx.
I can provide (sanitized) full debug output if it will help, unfortunately I don’t have any prior to May 23rd.
Is there a question here?
I’m pretty sure nothing has changed with influxdb code in a long time.
How is the performance of your influxdb server/cluster? Perhaps you hare having an issue on that end.
I’l profiling it now, but on that side nothing changed either. Aside from Libre which currently has 30 hosts, there are several shell scripts that at most were injecting maybe a thousand data points per minute (averaged between my 1 minute and 5 minute scripts). It just suddenly went from running fine to not fine at all, and Libre was the only thing affected. The other things interacting with it showed no change at all. When Libre was pushing metrics the Influx box was sitting at .25 load average, and a I/O wait of 1%, at most.
I guess my question would be: how hard would it be to change the Influx code to batch the insert instead of doing it in the middle of polling? data going into Influx is nice to have. But having the poller finish my core switches is more important (normally 120 seconds for a 6509 with 240 ports and 1k vlans, with the Influx issue went to 600+).