12vCPU; 64GB RAM; NVMe SSD all flash SAN with dual 10GBe; Network with dual GBe; Debian 12; single LibreNMS instance running on ProxMox HA cluster; 569 hosts
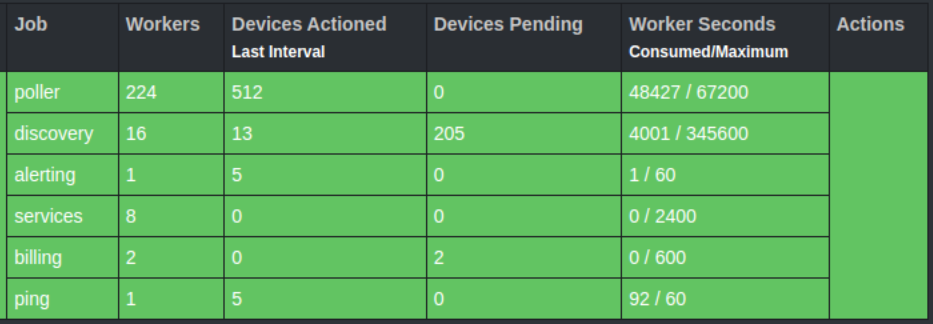
We were using the cron based poller which couldn’t complete an entire polling cycle. We moved to the librenms service and made some tweaks. We had to increase the poller workers and increase max_connections for MariaDB.:
I agree, it is quite a number. I started out with 16, then 24 and continued to increase the count until it was finally able to poll all devices in under 300 seconds. I also had to increase max_connections in MariaDB as I found out I had to increase both.
I had seen many devices in the 100-200+ second range (there were many well below that range). The system has been running well for almost 72 hours now.
I also increased max_repeaters (150) and max_oids (75) as well.
This was after running the mysql tuner and making adjustments there too. I still need to optimize php.