Hi,
after a small issue with my environment which included unplanned downtime (as a reason for sudden inconsistencies) I noticed that rrd is for some reason not saving correct values any more for 2 of my services:
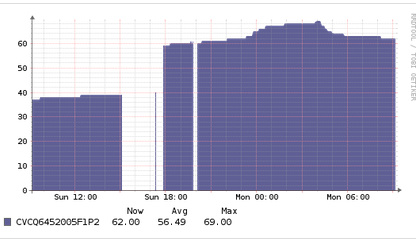
The gap was the downtime, the jump shows the incorrect temperature increase its showing for CVCQ6452005F1P2BGN (the others are fine it seems)
Nagios Service - 26
Request: /usr/lib/nagios/plugins/check_by_ssh -H esx37 -4 -C “sh /tmp/check_esx_smart_drive_temperatures.sh” -l root -i /opt/librenms/.ssh/vmware.key -t 30
Perf Data - DS: CVCQ6452005F1P2BGN, Value: 37, UOM:
Perf Data - DS: PHMB736000ML280CGN, Value: 41, UOM:
Perf Data - DS: S2HTNX0HB00039, Value: 62, UOM:
67F407560C2400150309 exceeded 19 characters, renaming to 67F407560C240015030
Perf Data - DS: 67F407560C240015030, Value: 70, UOM:
Perf Data - DS: S1YJNX0H503133, Value: 61, UOM:
Perf Data - DS: PHMB736100V5280CGN, Value: 49, UOM:
Response: OK - esx37: Temp check is running
Service DS: {
“CVCQ6452005F1P2BGN”: “”,
“PHMB736000ML280CGN”: “”,
“S2HTNX0HB00039”: “”,
“67F407560C240015030”: “”,
“S1YJNX0H503133”: “”,
“PHMB736100V5280CGN”: “”
}
RRD[update librenms/services-26.rrd N:37:41:62:70:61:49 --daemon unix:/var/run/rrdcached.sock]
This (and any manual script run) looks fine but the graph and underlying rrd file don’t agree with that:
rrdtool info /opt/librenms/rrd/librenms/services-26.rrd filename = “/opt/librenms/rrd/librenms/services-26.rrd”
rrd_version = “0003”
step = 300
last_update = 1534749335
header_size = 9440
ds[PHMB736100V5280CGN].index = 0
ds[PHMB736100V5280CGN].type = “GAUGE”
ds[PHMB736100V5280CGN].minimal_heartbeat = 600
ds[PHMB736100V5280CGN].min = 0.0000000000e+00
ds[PHMB736100V5280CGN].max = NaN
ds[PHMB736100V5280CGN].last_ds = “37”
ds[PHMB736100V5280CGN].value = 1.2950000000e+03
ds[PHMB736100V5280CGN].unknown_sec = 0
ds[S2HTNX0HB00039].index = 1
ds[S2HTNX0HB00039].type = “GAUGE”
ds[S2HTNX0HB00039].minimal_heartbeat = 600
ds[S2HTNX0HB00039].min = 0.0000000000e+00
ds[S2HTNX0HB00039].max = NaN
ds[S2HTNX0HB00039].last_ds = “41”
ds[S2HTNX0HB00039].value = 1.4350000000e+03
ds[S2HTNX0HB00039].unknown_sec = 0
ds[CVCQ6452005F1P2BGN].index = 2
ds[CVCQ6452005F1P2BGN].type = “GAUGE”
ds[CVCQ6452005F1P2BGN].minimal_heartbeat = 600
ds[CVCQ6452005F1P2BGN].min = 0.0000000000e+00
ds[CVCQ6452005F1P2BGN].max = NaN
ds[CVCQ6452005F1P2BGN].last_ds = “62”
ds[CVCQ6452005F1P2BGN].value = 2.1700000000e+03
ds[CVCQ6452005F1P2BGN].unknown_sec = 0
I assume I could simply drop the file and it likely would recover, but I don’t want to loose the historic data if i can help it and I wonder why that happens…
Thanks