Firstly, I’d like to apologise, I realise this is elementary stuff but I’ll be darned if I can wrap my head around this properly.
I use uptime kuma to monitor some things, it’s basic but good.
It has a heartbeat interval (60s)
I then have it fail at least 3 times in a row, before it contacts me. (Total, 180seconds)
(varying on the system of course)
I can easily change both of those figures.
What this means is 9 times out of 10 when it contacts me, it’s not a false alert.
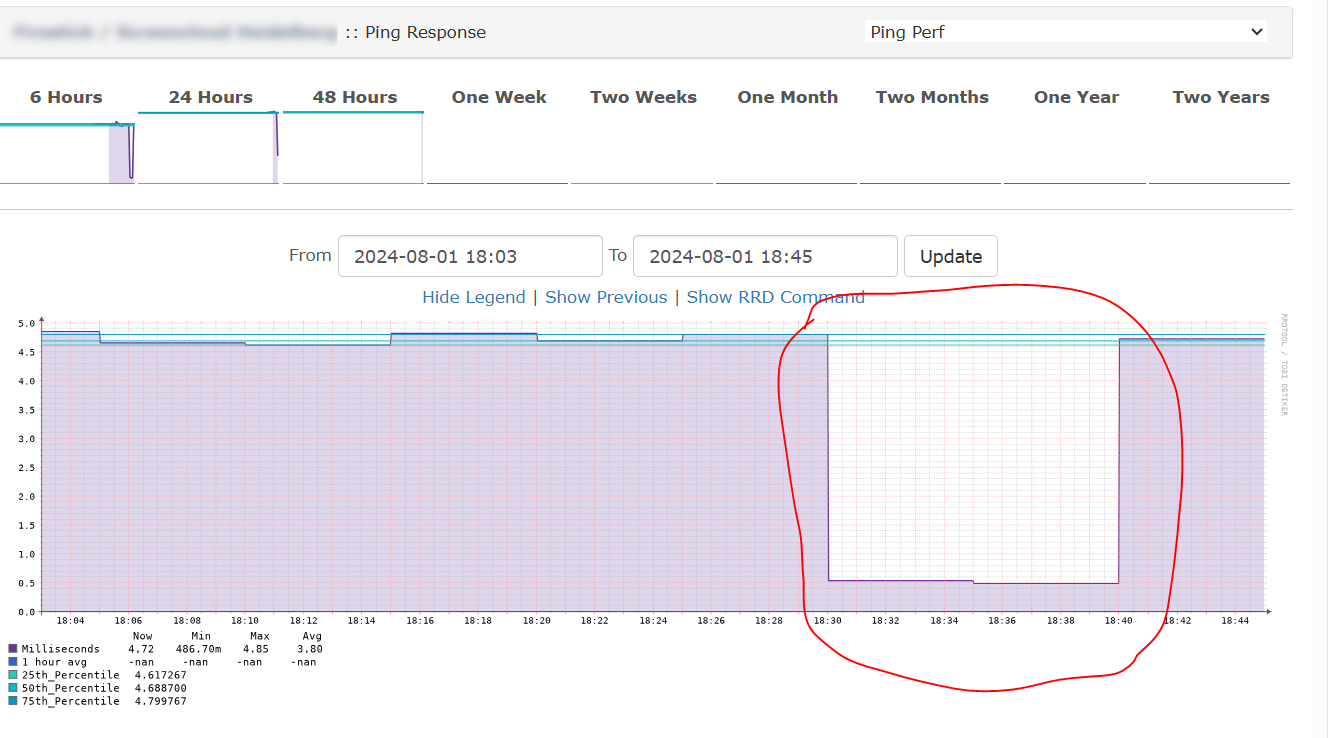
With LibreNMS I seem to be constantly getting alerts, even if a machine was briefly not contactable for 10 seconds. (We have some devices which auto reboot every 12 hours and take about 5 minutes to come back online, for example)
How do I have it, so that LibreNMS will ping (poll?) a device and it must fail at least 3x longer, before it reports an alert and it must have been down, those 3 times, consecutively?
Also and mostly on topic, does anyone know please, where can I confirm the current polling rate that it’s operating at? (Not where or how to change it, where to see what it currently is)
I think I’ve changed this, but I’d like to know if I did it correctly.
Thanks so much, again, I’m sorry - I’ve honestly read a few times but I continue to get alerts which are not actually real.
As for polling rate, It’s determined by your cron entry and replicate the same in the poller settings. More info found here for an example of 1 minute polling - 1 Minute Polling - LibreNMS Docs
Firstly, thank you.
Secondly, oh my goodness, it says 500ms…
Is that actually 500ms? Fping count is 3. So would that imply 1.5 seconds before a host is marked down?
As I previously mentioned, uptime Kuma, I’m unsure what the fping / ping interval is for latency checks, but for service down I can define it myself, see here: bJYYL1l.png (1142×659) (imgur.com)
For this one, it would take a solid 360 seconds, before alerting me.
Actually those ping times in settings that might be just for services such as the latency check. I could be wrong
If you read the above it gives an explanation how the ping check works. “Normally, LibreNMS sends an ICMP ping to the device before polling to check if it is up or down. This check is tied to the poller frequency, which is normally 5 minutes. This means it may take up to 5 minutes to find out if a device is down.” This is based on the ping cron entry
So I hope this doesn’t agitate you or anyone else, but I do continue to see people send people to the 1m polling article, to change cron to adjust the polling rate.
However,…
I’m one of those folks running librenms on docker, with this excellent bit of work here:
I’ve followed his instructions to adjust the polling rate, but I don’t know where to look up a flag in the running system which confirms that I actually did, properly adjust the rate. (crontab -l does not work, while exec’d into the container)
I can see " * service_poller_frequency300" in the global settings but that is not the figure I tried for (3 minutes, instead of 5)
Is that the poller?
Just to clarify, the second link, the fast ping option isn’t really about changing the polling rate. Polling being a full gathering of SNMP/services/etc. It’s about adding a new cron entry for running up/down pings every 1 minute. So without any other changes, you poll every 5min, ping every 1min.
That fast ping doc page explains that it works differently than normal polling in terms of fping count.
ping.php uses much the same settings as the poller fping with one exception: retries is used instead of count. ping.php does not measure loss and avg response time, only up/down, so once a device responds it stops pinging it.
So 1 good ping means the device stays marked UP. 1 bad ping with 1 retries and 500ms interval set means that it’ll wait 500ms, ping again and if still bad will mark DOWN.
So I believe enabling 1min fast ping with a 3min delay configured on your alert rule should be about as you describe the heartbeat checks on your other system.
I’ve never seen this docker image, so I’m not sure I can be of much help there. At a quick glance I don’t see an easy option to add fast ping to its cron jobs, maybe something the maintainer could add if you created an issue?
service_poller_frequency I believe is only for the dispatcher service. So with that docker image using cron, it shouldn’t apply. It seems to have its own method if you really want to do 1min full polling instead of fast ping.
See the POLLERS_CRON environmental variable at: readme-ov-file#enablingdisabling-librenms-features
Since the image is Ubuntu based you might be able to see confirmation with service crond status or just tail -f /opt/librenms/logs/librenms.log and see if you see groups of INFO: device:poll messages coming in every minute.
I’m very sorry to ‘not get it’ I really apologise, once this clicks for me, I’ll feel much better.
I just want to make my alerting set to a reasonable figure which won’t antagonise people or create false alerts over a system rebooting that takes 3 to 7 minutes for example. I want to configure, ideally, per device - how long the device needs to be offline before I even care at all.
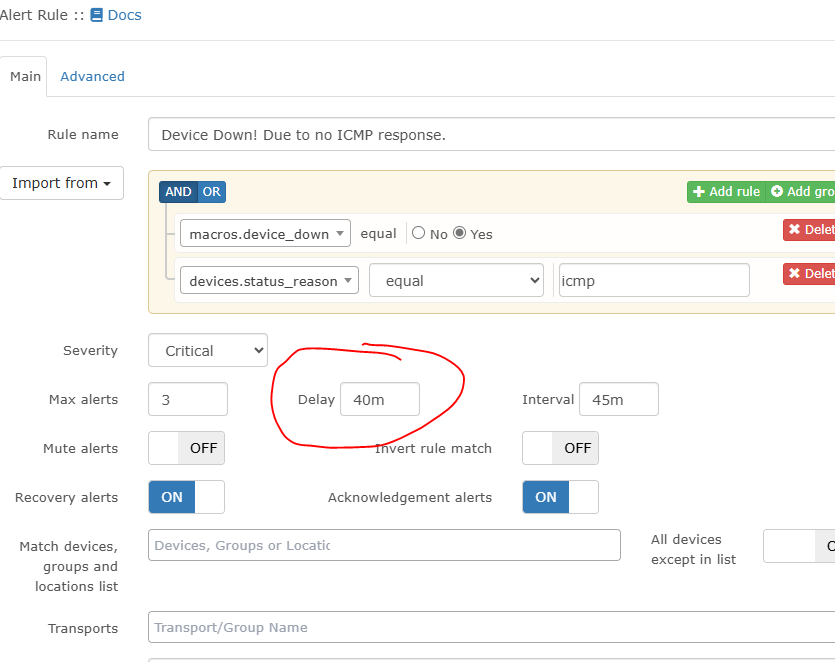
My understanding is the ‘delay’ is for alerting via the Alert Transport only, not to delay events. If you had a transport added to that alert (such as email you it’s down) then it’ll follow the delay rule that it wont email you until after 40 minutes it’s been triggered as down, so long as its still down.
You don’t have a transport added so the max alert/delay/interval would do nothing.
Perhaps I’m looking at this the wrong way. The system has to check regularly, the system will always flag as an issue and I can only delay the notification of the issue?
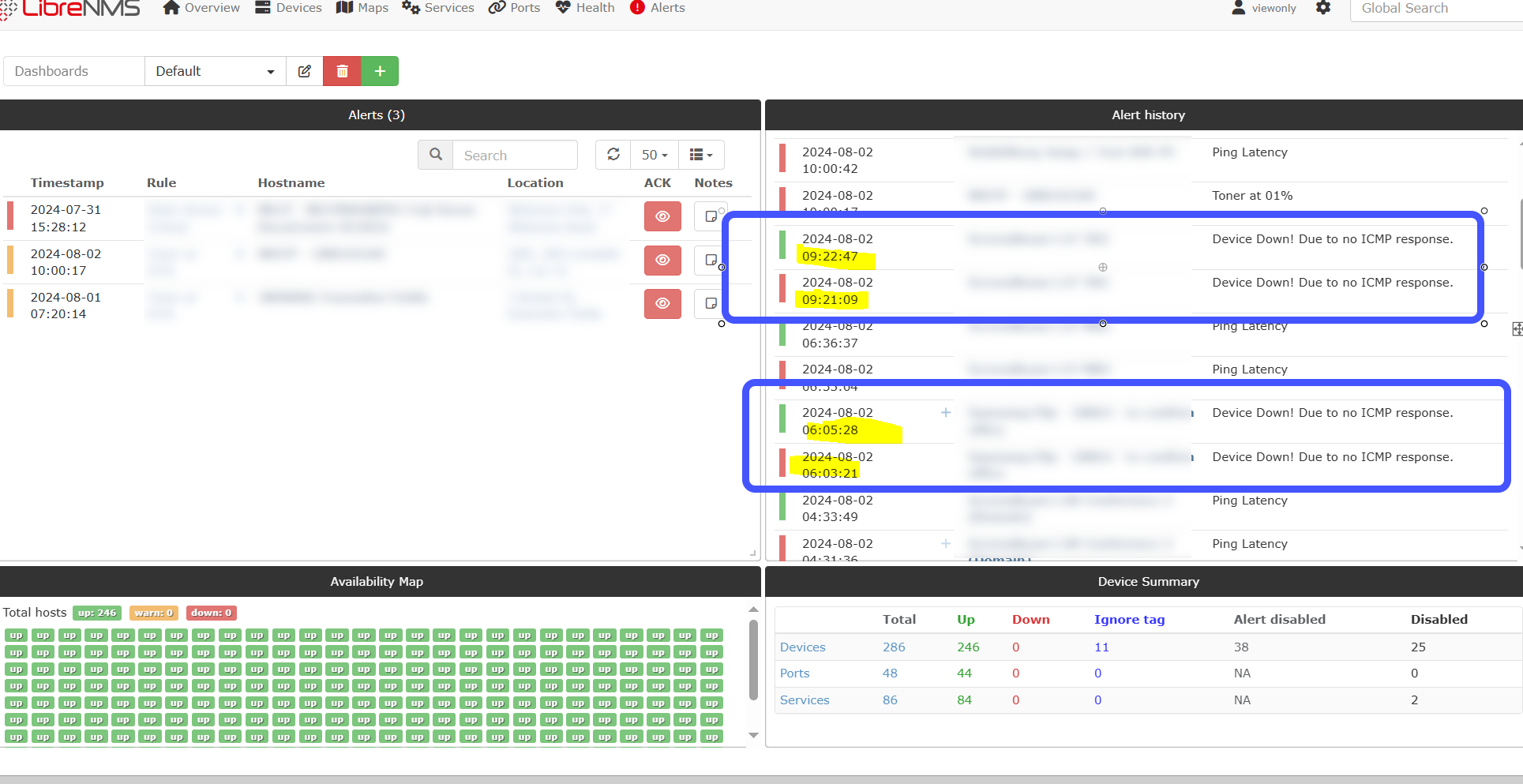
In my dashboard console, I have current alerts and alert history, for my colleagues.
I see what you’re trying to do. My suggestion is maybe split your devices into different device groups based on severity? That way you can could have different dashboard widgets to report on different device groups of serverity. Then you could configure different rules for the different device groups so the alert transports trigger to how you want them based on the device groups.
Alternatively you could adjust the ping times in the global settings but i wouldn’t recommend doing that if you have devices out for as much as 3 minutes, plus that affects all your devices.
This is definitely tricky then, I surely can’t be the only one who would like it to function that way. The tool makes an excellent dashboard but the wrong people walking past seeing constant “up / down” history for things is not good.
@ski522 and @walleyeguy seem to be discussing similar things in this thread here:
Maybe I need to recreate my dashboard somehow and have a new kind of panel like “Alerts ACTIVE” only on display with no history?
This is a real shame thus far because this does vastly more for me than uptime kuma, but I can’t (seem?) to individually customise my alerts per machine. Whereas Kuma will let me say “this server reboots for 18 minutes so don’t alert me unless 23 minutes” and “this link should never be down more than 45 seconds”
I’ll have a crack at explaining this further. The monitoring is done from the cron tasks if you have, which is a global scan for the poller wrapper, pings and alerts to name a few. Since these scans are global, they aren’t configured to run on a per-device basis but rather across all devices simultaneously. This is why you cant simply set different devices to different ping times. Maybe there are more advanced configuration to set different device groups to different cron task times but that’s well beyond my experience.
My example below is my cron tasks for pining and alerting to happen every 30 seconds so I’m aware across ALL my devices to report within 30 seconds if they are down.

{kind=link}