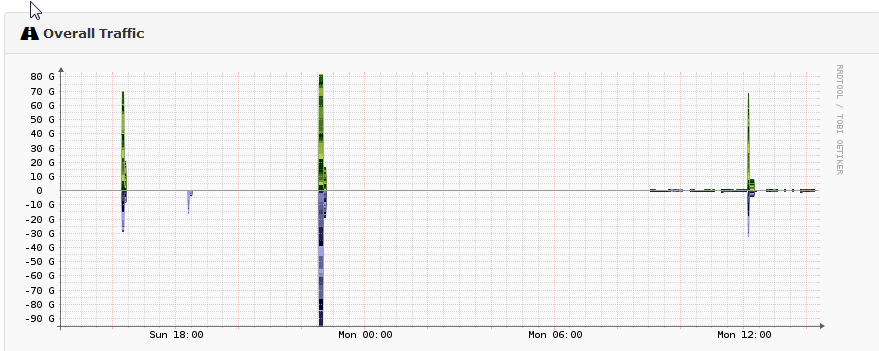
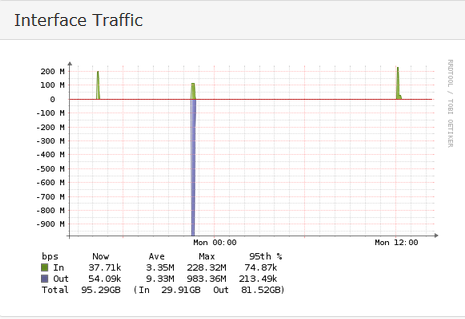
I’m monitoring loads of hosts, and all are working perfectly fine, except one - a Cisco 6800K VSS chassis (i.e. two running as a failover pair). My overall traffic graphs, and some interfaces are looking this this:
I’ve set rrdtune to enabled, I’ve manually ran rrdtune against the host, and I’ve run the removespikes command, but none of it is making a difference. I just randomly get these massive spikes. It seems to be happening on the L3 VLAN interfaces (the second graph). It’s a distribution switch, so all the VLANs are L3, and then trunked out. If I look at the corresponding VLAN on the access switch, I sometimes see a spike, but it’ll be tens of Mb/s, not hundreds. Sometimes there’s nothing corresponding at all. The VLAN interface identifies as being 1Gb/s virtual within LibreNMS.
I know the PHP on the server is technically out of date (still on 5.x), but it’s working perfectly otherwise. I’m planning to build a new LibreNMS box and migrate soon, as well as having a remote poller going, so I’ll upgrade then.
When you ran RRDTune for those interfaces did you also run the scripts?
Now when a port interface speed changes (this can happen because of a physical change or just because the device has misreported) the max value is set. If you don’t want to wait until a port speed changes then you can run the included script:
./scripts/tune_port.php -h -p
Wildcards are supported using *, i.e:
./scripts/tune_port.php -h local* -p eth*
This script will then perform the rrdtool tune on each port found using the provided ifSpeed for that port.
I did, but now I think about it, I ran it against all the 10-gig interfaces because I’d seen one of those with spikes. The VLAN interfaces didn’t occur to me (I’d not noticed one spiking).
I’ll run it again as -p vlan* and see what happens.
Edit: I actually ran:
./scripts/tune_port.php -h x.x.x.x -p all
Looks like I did tune them all anyway. I’ll try again with vlan* just in case.
I can explain in general what causes spikes. (just for some base knowledge)
SNMP ifInOctets and ifOutOctets are counters, which means they start at 0 (at device boot) and count up from there. LibreNMS records the value every 5 minutes and uses the difference between the previous value and the current value to calculate rate. (Also, this value resets to 0 when it hits the max value)
Now, when the value is not recorded for awhile RRD (our time series storage) does not record a 0, it records the last value, otherwise, there would be even worse problems. Then finally we get the current ifIn/OutOctets value and record that. Now, it appears as though all of the traffic since it stopped getting values have occurred in the last 5 minute interval.
So whenever you see spikes like this, it means we have not received data from the device for several polling intervals. The cause can vary quite a bit: bad snmp implementations, intermittant network connectivity, broken poller, and more.
Anyway, just posting this here for posterity, good luck.
Now that’s very useful to know. That’s for the excellent explanation. Looking at the graphs, it now makes more sense. It seems last night it didn’t fully poll between 9pm and 3am. At 3am there’s a massive spike, and it would appear to be the traffic for that six-hour window totalled up. However, other graphs are adding up correctly.
I’ll check the SNMP config on the switch and see if there’s anything goofy set for the interfaces. It seems to be the L3 VLAN interfaces causing the issue, so it gives me somewhere to focus. Incidentally, I’ve got Cisco 4500 switches in a similar config and they are behaving.
 perhaps a distilled version in the docs if we have a section that talks about spikes.
perhaps a distilled version in the docs if we have a section that talks about spikes.