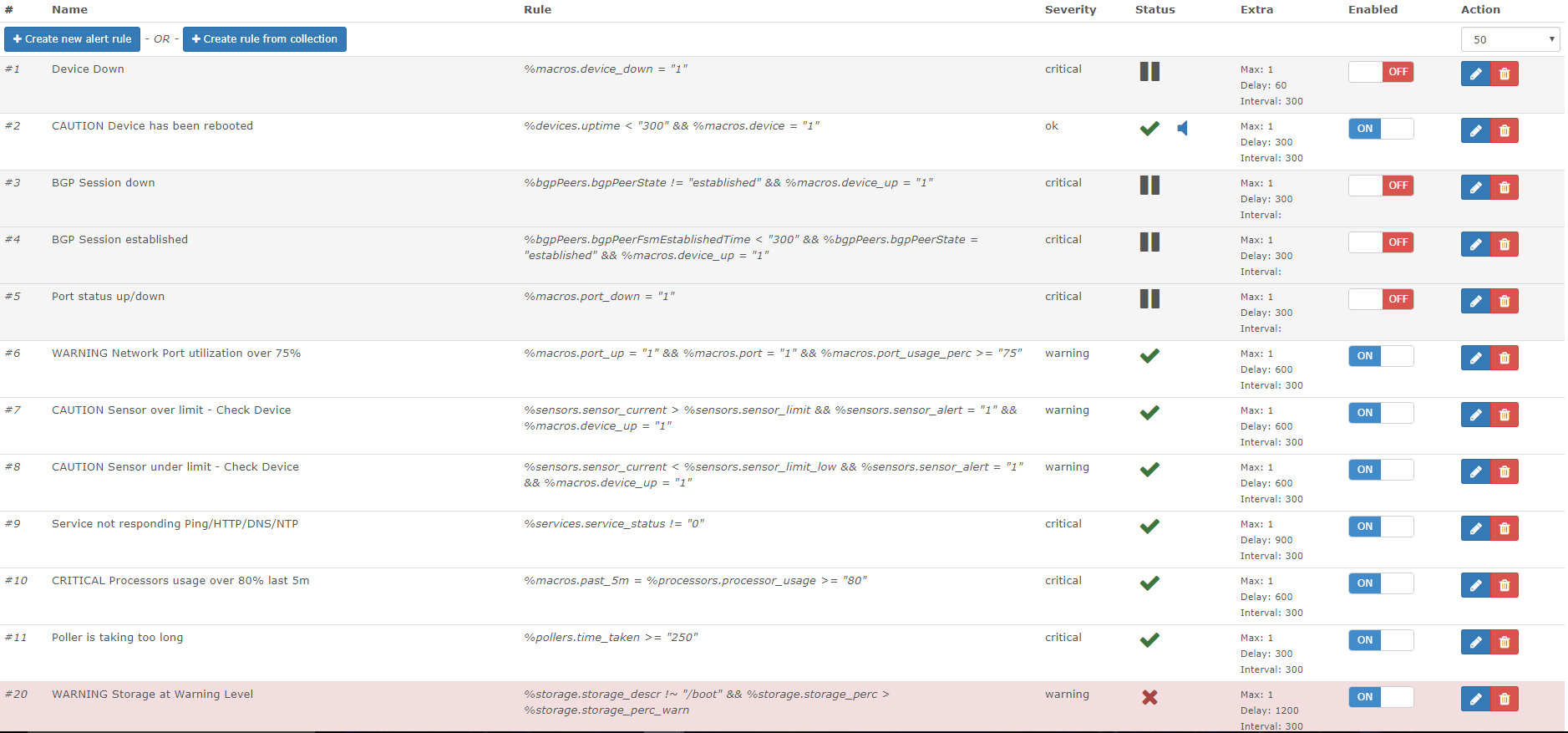
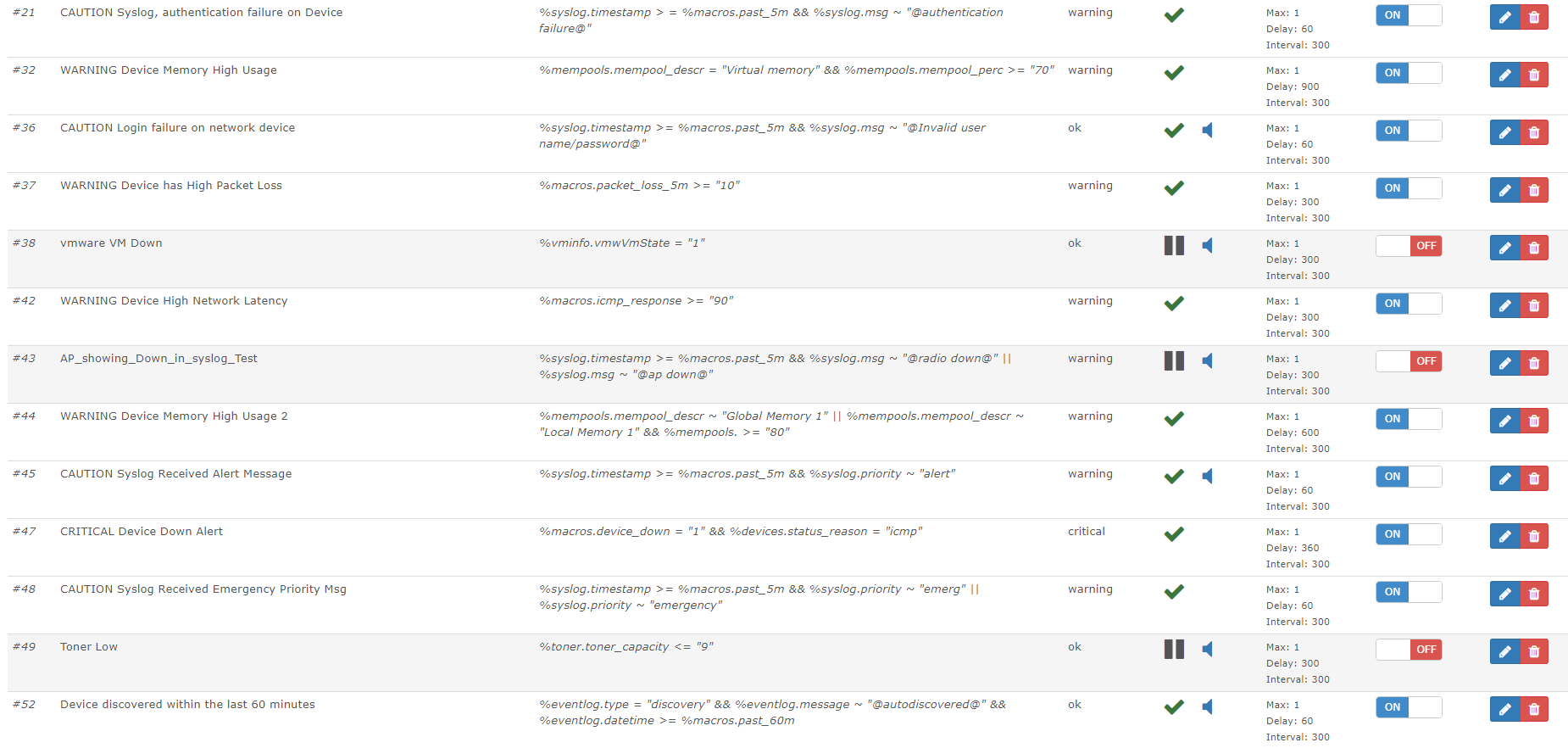
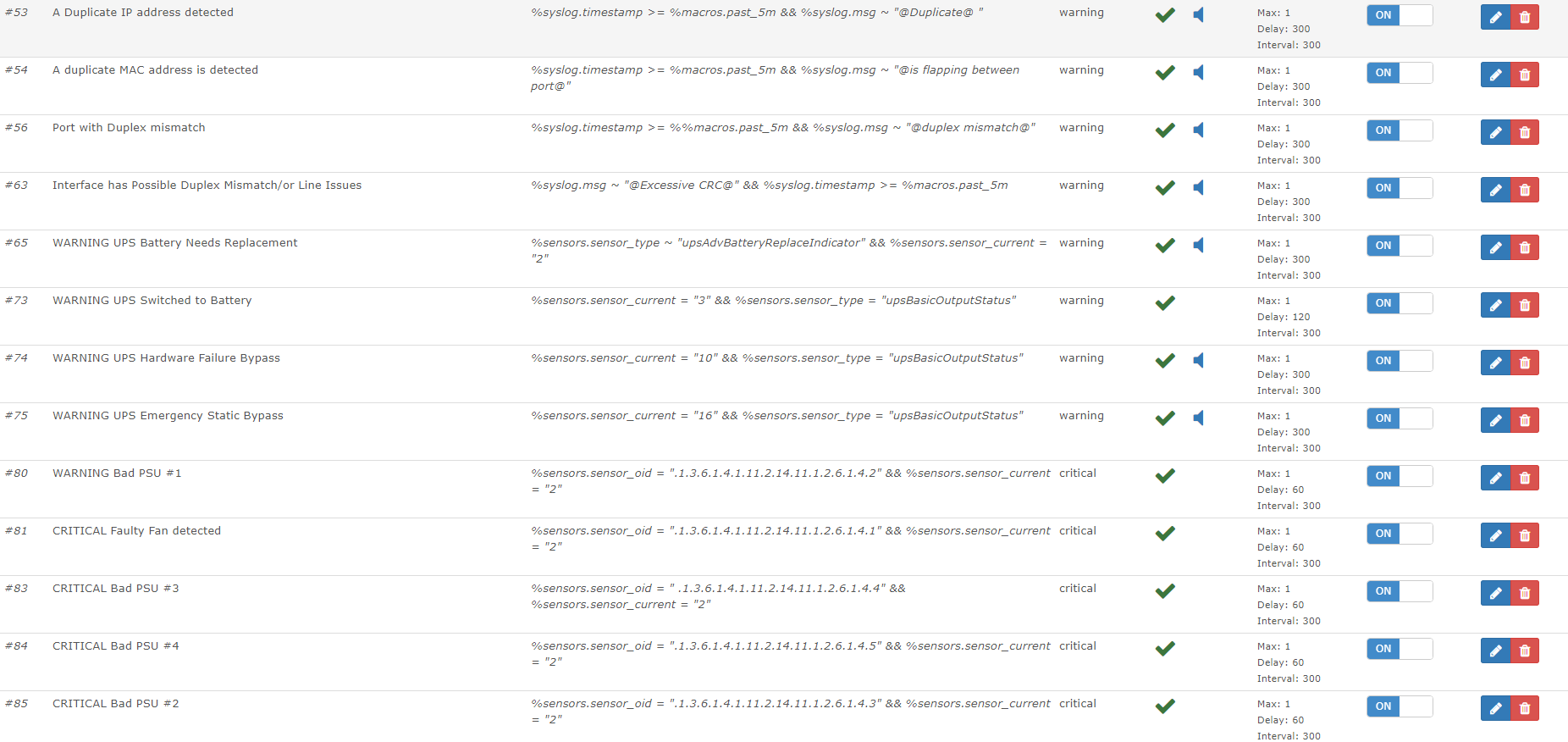
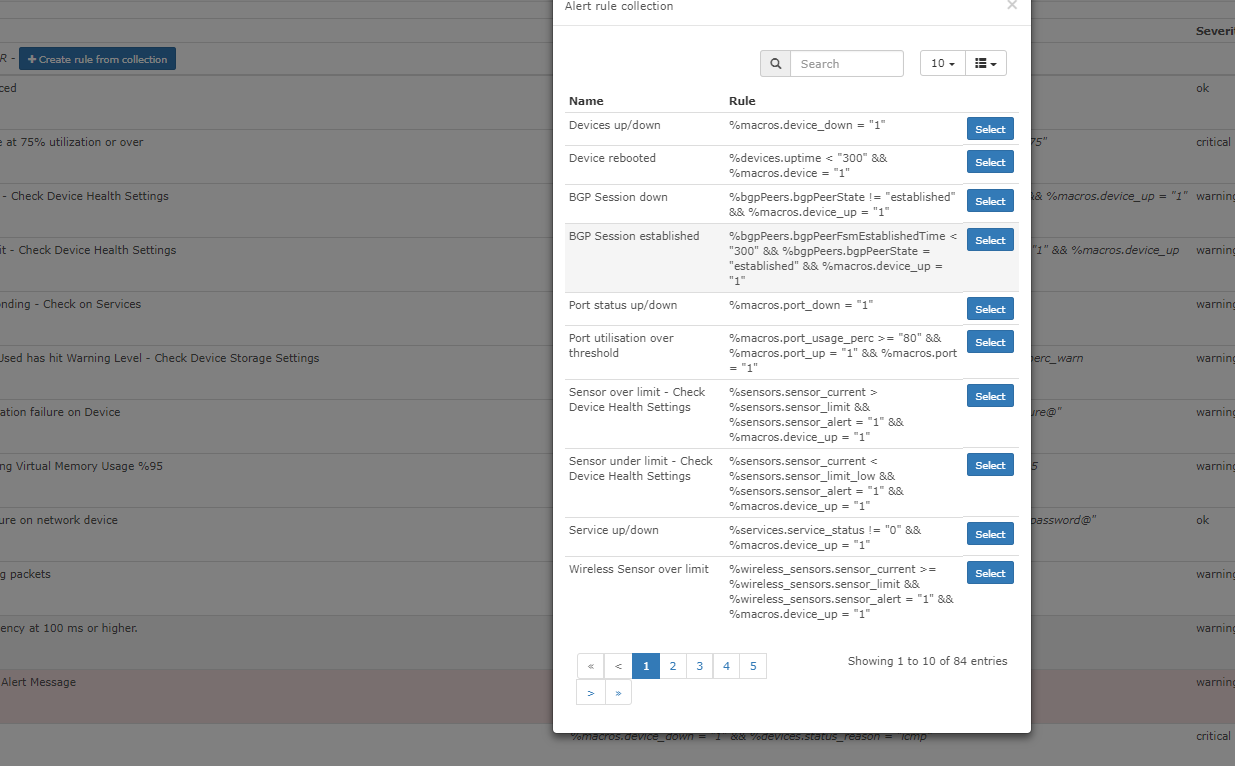
LibreNMS is not very plentiful with their example alerts. It took me a significant amount of time to come up with the following rules so I thought I would create a repository to retain them in the event that I need to rebuild my LibreNMS server in the future.
I’m looking forward to seeing what rules the rest of the community has designed. Here are some other things I would be interested in monitoring:
Disk IOPS
CPU Contention
Disk Read/Write Latency
Memory Contention
HTTPS Endpoint Availability
ICMP response time
Successful/Failed SSH/RDP connection initiation
PS: If you have any feedback for the Alert-related issues described in the TODO section of the GitHub README I would love some insight.
However, to fine tune this, for the servers with huge disks percetages should be higher. In nagios I would create different host groups for these kinds of servers, but nevermind we’ll get there in good time.