Hello,
I need some help with debugging a zombie process issue with my LibreNMS install. Everything was setup using the install docs. I run the dispatcher service and rrdcached. Using 5 minute polling for approximately 60 devices with plans to add more. On Monthly update cycle for stability reasons. Also integrated with smokeping.
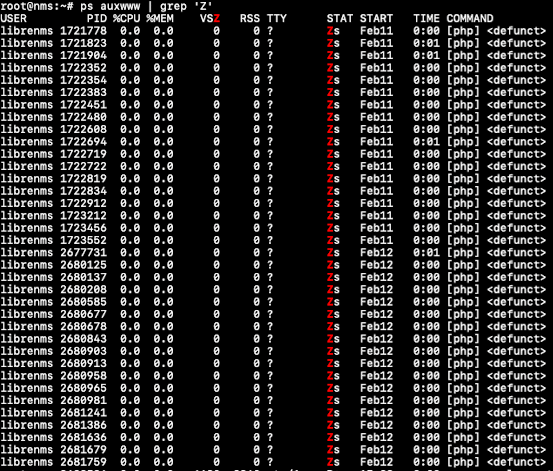
Currently I am showing 18 zombie processes under the librenms user. They go away when I restart the librenms service only to reappear after a few hours it seems. When I run the top command, it shows the following:

Output of ps command displays the following: https://pastebin.com/sQ01jRr6
My setup is as follows:
Server: Dedicated VM instance on Linode with 4 CPU cores and 8GB RAM
OS: Ubuntu 22.04 LTS
Web Server: nginx 1.18.0
PHP-FPM: 8.1.2
Mariadb: 10.6.16
Python 3.10.12
rrdtool: 1.7.2
validate.php and daily.sh scripts return no errors: https://pastebin.com/R9L0xshC
Checked all log files (librenms.log, daily.log, maintenance.log, php8.1-fpm.log, nginx error logs) All look good with no reported errors.
Here are my conf files for php-fpm and nginx: https://pastebin.com/jMsKN4Y6
I hope I have provided enough info here for someone to assist. If there is something more that you require, please let me know and I’ll post it. I’ve spent almost 2 weeks trying to debug this with no success. A google search on the issue doesn’t return much except one other article on defunct processes that suggests it’s an issue with PHP that the developers won’t fix. Another user posted a possible solution but not quite sure that I understand it or if it pertains to my issue.
The server seems to run normally and I am not getting any gateway timeouts. Devices appear to poll normally and graphs are displaying.
Thanks in advance for the help.
Jaysen