Thanks @murrant.
I have decided to change only the main troublesome device at site and left the rest to see if it makes a difference.
Based on: Configuration Docs - LibreNMS Docs and Performance - LibreNMS Docs
I have changed repeaters to 70, and timeout to 3, which was previously using defaults of 1 second and zero repeaters:
~$ ./lnms config:get snmp
array (
----
'max_repeaters' => 0,
'timeout' => 1,
----
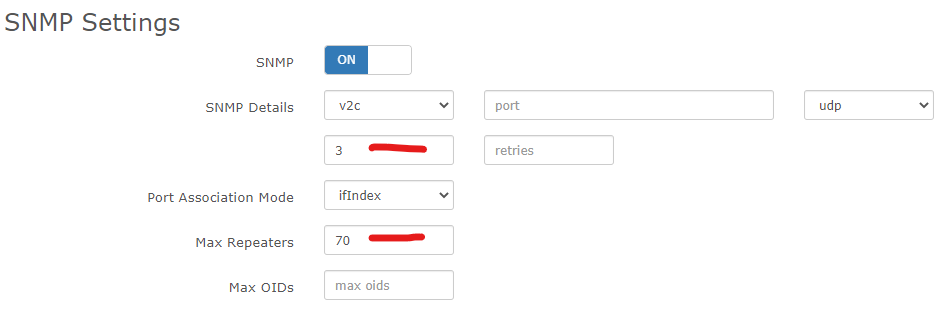
Some max repeaters testing on this device:
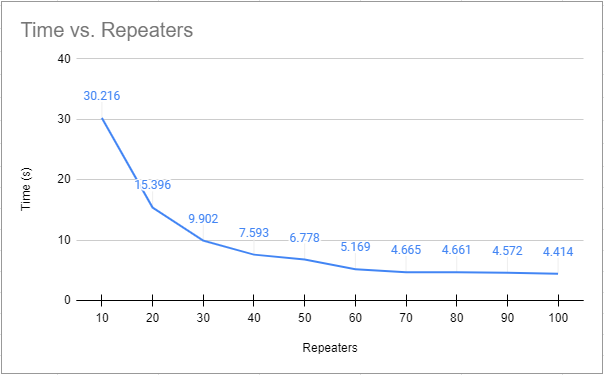
In good times and while testing repeaters above, the latency on the link is pretty consistent, and the connection is stable:
~$ sudo sudo ping -f 10.x.x.x.x -c 500
PING 10.x.x.x (10.x.x.x.x) 56(84) bytes of data.
--- 10.x.x.x.x ping statistics ---
500 packets transmitted, 500 received, 0% packet loss, time 8094ms
rtt min/avg/max/mdev = 528.096/595.453/763.771/36.694 ms, pipe 46, ipg/ewma 16.221/615.453 ms
However I’ve found one device with working smokeping from the time of the last spike, and it’s evident there is congestion and packet loss:
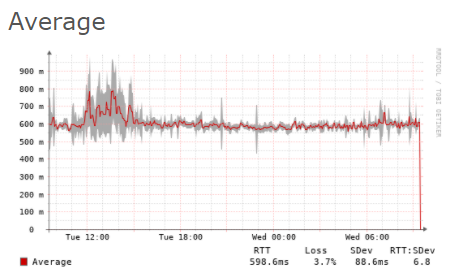
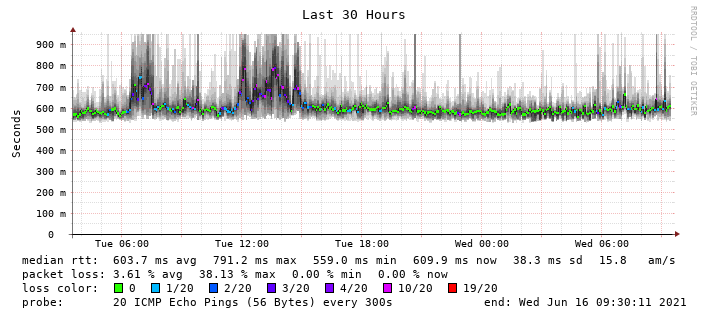
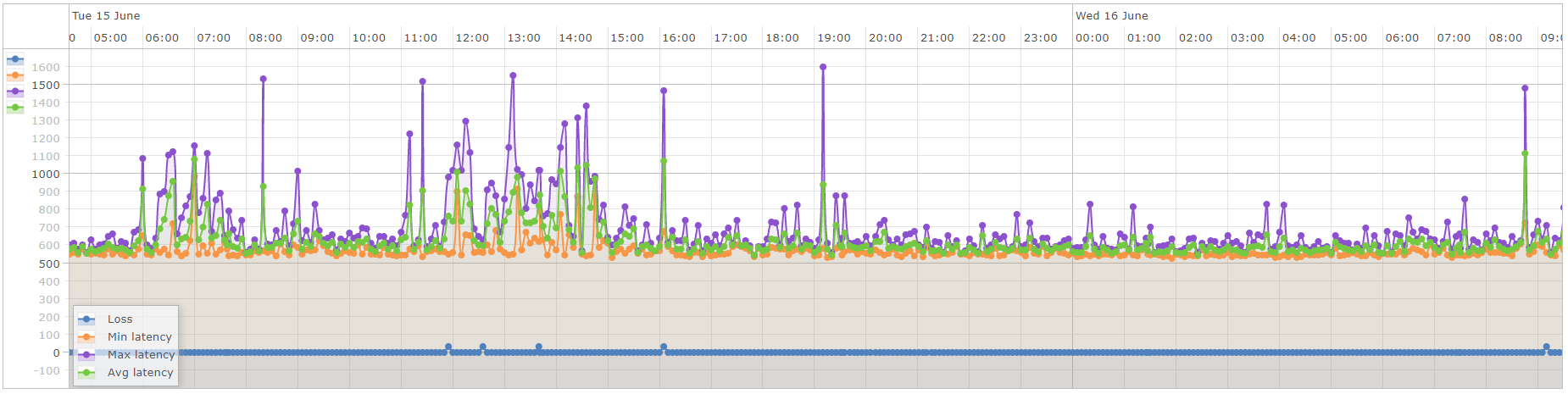
Given this will be inevitable, I’m focusing on how to keep his from destroying my graphs as best as possible.