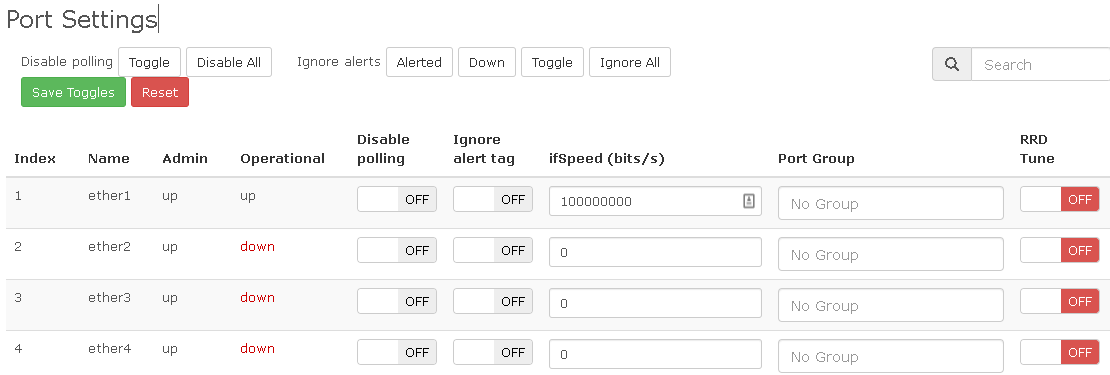
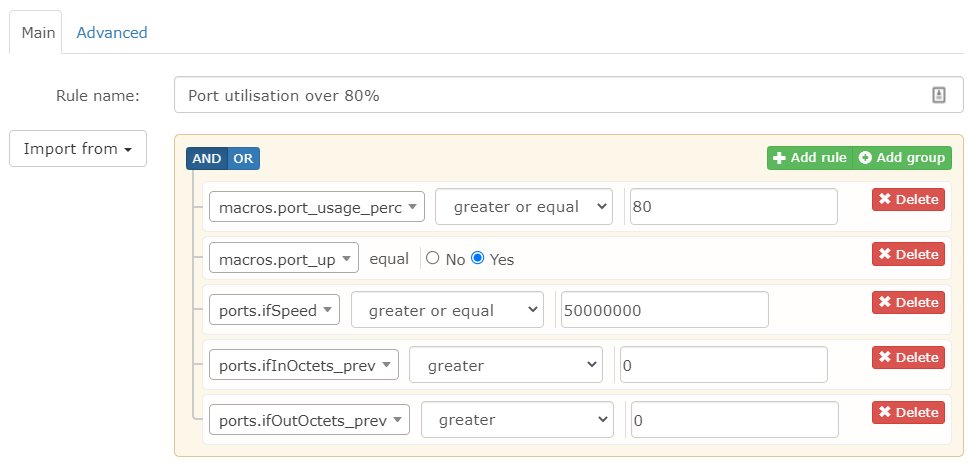
I recently set up ethernet port utilisation alerting for switch ports, and after a bit of tuning of the alert and template it works really well, except for one thing.
We have one switch which from time to time stops responding to SNMP (and web interface) for periods of time around 5-30 seconds so that there are the occasional 5 minute polling periods (a few per day) where LibreNMS is not able to poll SNMP on the device, and then in the following polling period it can again.
This switch frequently sets off bogus port utilisation alerts around the time these failed SNMP sessions occur. Here is an example alert with some amusing values in it:
Device Name: finance
Operating System: D-Link Switch 7.20.003
Hardware: WS6-DGS-1210-24P/G1
High utilisation ports:
#1: Port: Slot0/1
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 1
Link Rate: 100 Mbit/s
Receive Rate: 45,027.46 Mbit/s
Transmit Rate: 1,578.57 Mbit/s
#2: Port: Slot0/6
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 6
Link Rate: 1,000 Mbit/s
Receive Rate: 13.80 Mbit/s
Transmit Rate: 937.30 Mbit/s
#3: Port: Slot0/10
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 10
Link Rate: 100 Mbit/s
Receive Rate: 0.06 Mbit/s
Transmit Rate: 749.00 Mbit/s
#4: Port: Slot0/17
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 17
Link Rate: 100 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 748.95 Mbit/s
#5: Port: Slot0/18
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 18
Link Rate: 1,000 Mbit/s
Receive Rate: 38.70 Mbit/s
Transmit Rate: 3,319.43 Mbit/s
#6: Port: Slot0/19
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 19
Link Rate: 1,000 Mbit/s
Receive Rate: 196.46 Mbit/s
Transmit Rate: 1,480.07 Mbit/s
#7: Port: Slot0/21
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 21
Link Rate: 1,000 Mbit/s
Receive Rate: 186.88 Mbit/s
Transmit Rate: 2,398.79 Mbit/s
#8: Port: Slot0/22
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 22
Link Rate: 100 Mbit/s
Receive Rate: 10.41 Mbit/s
Transmit Rate: 868.12 Mbit/s
#9: Port: Slot0/24
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 24
Link Rate: 100 Mbit/s
Receive Rate: 17.78 Mbit/s
Transmit Rate: 1,071.64 Mbit/s
#10: Port: Slot0/26
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 26
Link Rate: 1,000 Mbit/s
Receive Rate: 114.64 Mbit/s
Transmit Rate: 1,270.73 Mbit/s
#11: Port: Slot0/27
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 27
Link Rate: 100 Mbit/s
Receive Rate: 9.24 Mbit/s
Transmit Rate: 854.05 Mbit/s
#12: Port: Slot0/28
Port Name: Uplink
Port Description: D-Link DGS-1210-24P Rev.GX/7.20.003 Port 28
Link Rate: 1,000 Mbit/s
Receive Rate: 5,272.77 Mbit/s
Transmit Rate: 45,723.78 Mbit/s
The Link Rates ("ifSpeed") are all correct and the Receive and Transmit rates are pulled from ifInOctets_rate and ifOutOctets_rate in the template and are converted from bytes/sec to Mbit/sec for display.
Many of the figures reported here are ludicrously high so it’s obvious they are bogus and couldn’t even be caused by a network flood.
What seems to be happening is incorrect calculation of ifInOctets_rate and ifOutOctets_rate if the previous polling session failed.
It looks almost as if failing to poll a device logs “0” for the current network interface counters, then on the subsequent successful polling session the valid traffic counters are subtracted from 0 instead of the last known good counters, as a result random, crazy high “rates” are reported for one polling period dependent on the absolute values of the counters.
Obviously in the scenario of a polling session that didn’t succeed the last known good traffic counters should be used instead of zero when subtracting from the current counters, and the increased time period taken into account when calculating the rate. (Eg 10 minutes instead of 5, presumably the time at which each counter is recorded is also recorded so this should be possible)
The traffic graphs themselves seem to handle missed polling sessions gracefully - they just show a small gap. It’s just the calculation of the rate used for alerts which is not handling these polling gaps correctly.
I note that when we had an inadvertent broadcast storm for a few minutes recently (fat fingers on IGMP snooping settings) which caused the majority of our switches to miss responding to an SNMP polling period due to the flood, a relatively high percentage of them also triggered high port utilisation alerts with ludicrously high claimed traffic figures - just the same as this switch does. So the missed polling session does seem to be the cause of the rate calculation error.
Has anyone else noticed false triggering of port utilisation alerts due to missed SNMP polling sessions, and does anyone have a suggestion of a workaround?