[OK] Composer Version: 1.6.5
[OK] Dependencies up-to-date.
[OK] Database connection successful
[OK] Database schema correct
[FAIL] You have no timezone set for php.
[FIX] PHP: Runtime Configuration - Manual
[WARN] Some devices have not been polled in the last 5 minutes. You may have performance issues.
[FIX] Check your poll log and see: Performance - LibreNMS Docs
Devices:
[ a lot of devices…]
and 16 more…
[FAIL] Some devices have not completed their polling run in 5 minutes, this will create gaps in data.
[FIX] Check your poll log and see: Performance - LibreNMS Docs
Devices:
[more devices…]
==========================================
We migrated recently from the ‘old’ librems service to a new one. Polling for certain devices is super slow now, which was not a problem with old service - or even cron-based poller.
It looks like mostly Cisco Nexus devices are affected, but this could be because they have got the most interfaces/items to poll.
No errors or obvious problematic messages in service logs.
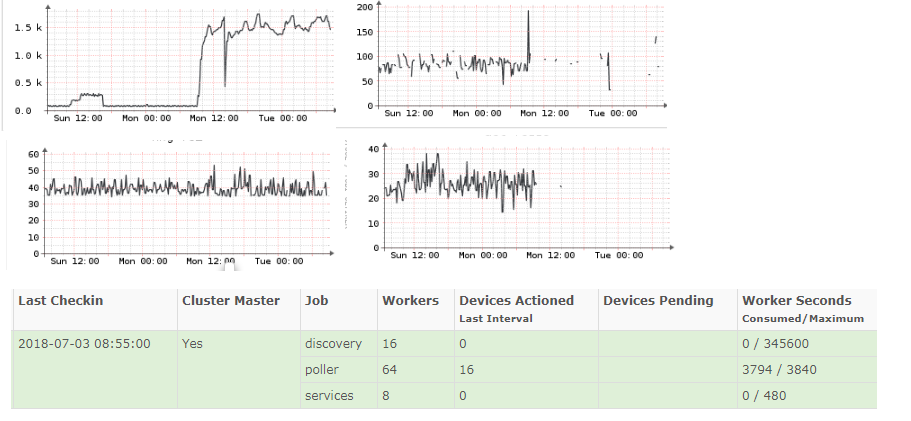
There are 106 devices in total, no distributed polling. We set new poller service with the same amount of threads (64) as the old one. 1 minute polling interval is what we use.
There are a few devices that took a bit longer than 60 seconds to poll in some cases with the previous service, but this was fine - we were just getting occasionally gaps in the graphs. Now polling pretty much never finishes for some of the stuff.
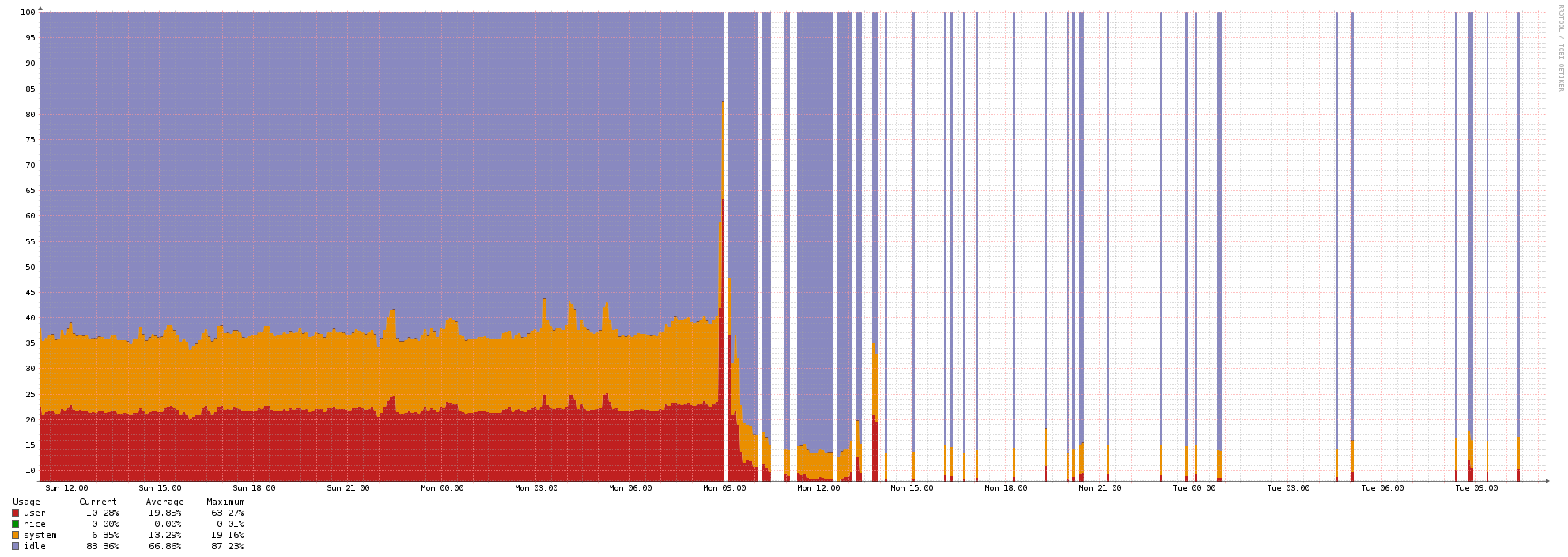
The load on the poller looks fine, no I/O wait (it is all sitting on SSDs anyway).
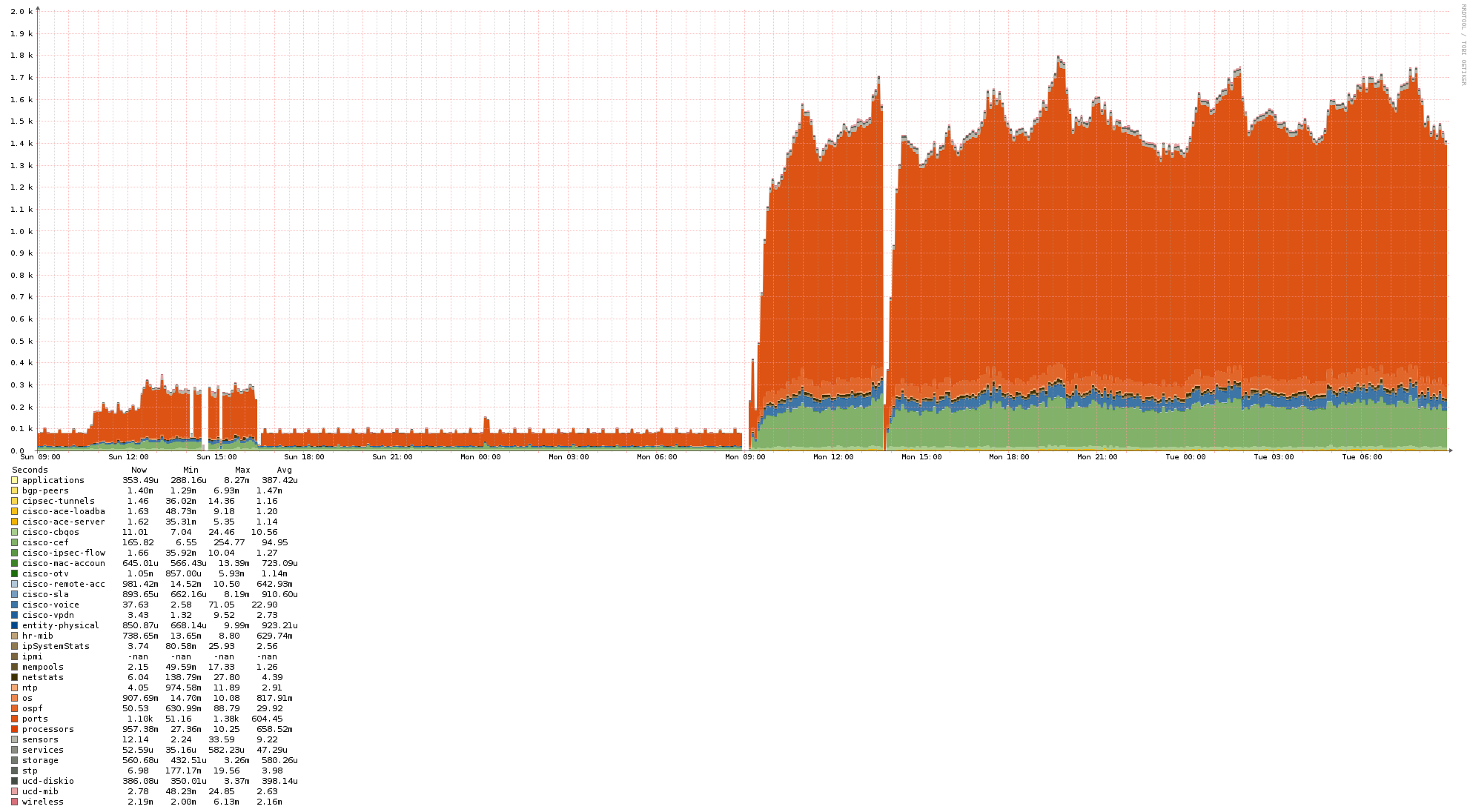
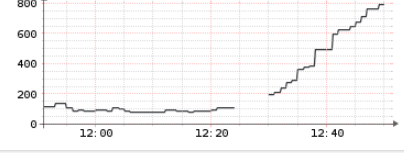
The CPU on the poller usage after migration to new service is much lower actually, at least from the snippets of data it shows (it struggles even with polling itself):
It looks like something is blocking/throttling/stalling the workers - so they are doing much less work (at least in certain scenarios) than in case of previous setup.
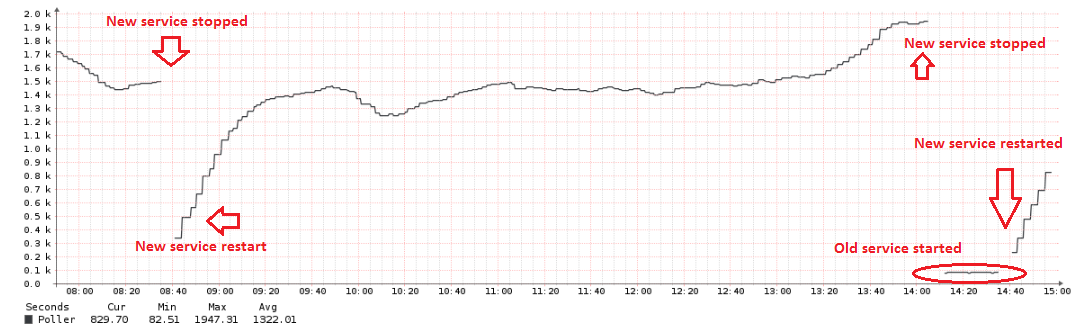
Thanks for checking, I can confirm that switching back to librenms-poller-service instantly fixes the problem (literally just by stopping librenms.service and restarting librenms-poller-service.service):
The old one exhibits consistently good performance.
Possibly the new service handles devices that exceed configured polling period in a different way (some stale or incomplete threads/ jobs keep accumulating slowing everything down?)
Just to let you know, I have just tried the new librenms.service again (was using legacy one due to these problems) with the latest and greatest version 1.52, but unfortunately the issue still persists:
However, it looks like the only devices affected by this at the moment are Nexus 5K, the polling graphs for other stuff look fine - have you got any idea what could it be?
Correct, this is the guy I have problem with (librenms-service.py)
The old service (poller-service.py) however works fine on the same box with the same setup
It really looks like only Nexus 5K devices are affected by this problem with new service at the moment - but the impact is rather dramatic. The only ‘special’ think about them I can think of is that they have got a lot of ports (more than our other network kit, generally), but it does not make sense still…
I had to remove hostnames, as they are rather sensitive, but marked Nexus 5Ks where applicable.
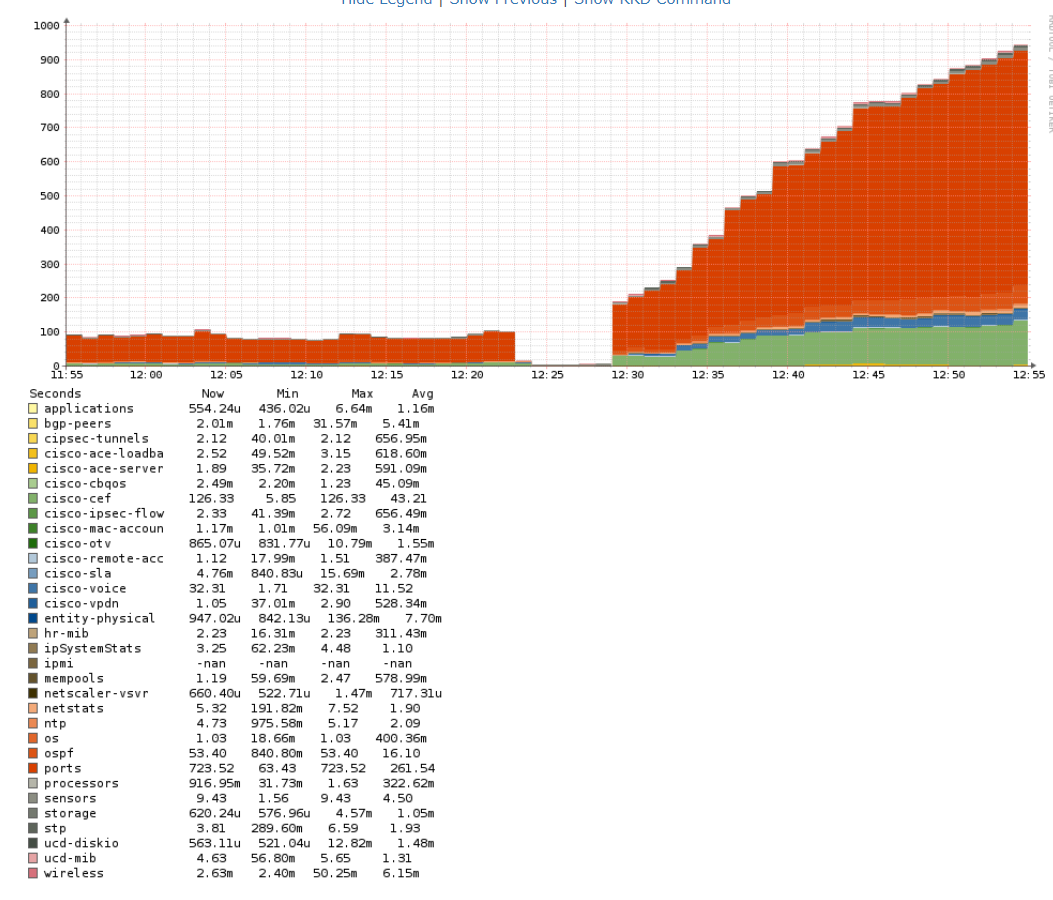
This new librenms-service.py service was active from around 12:00 to 16:00 - I reverted to old service at that point.
It looks like new service generally perform a bit better than old one across the board, except for these Nexus 5K devices (we have got 4 in total), where polling is simply catastrophically broken for some reason…
The old service also seem to spend a lot of time in ifXEntry, but in this case the process actually finishes within 30 seconds or so (or maybe old service script just kills it if it takes too long??)
systemctl status librenms-poller-service.service | grep nexus-hostname