Running this particular script took 122 sec in this case, since there was also regular poller hammering device at the same time. With polling disabled for this device, the output looks more like this:
The thing is that I have got around 150 devices in LibreNMS and polling for >140 of them finishes way within 60 seconds (on average 10 or so).
Those few which overrun, mostly don’t even overrun consistently (depends on the load on the device, etc) - in many cases they can still be done with polling within a minute or so, but happen to periodically have some ‘bad polls’ taking over a minute.
Obviously, the ideal case would be to be able to consistently poll everything < 60 sec, but this is not really realistic, with so many different hardware types and device types involved. We still very much want to use one minute polling, as the default value is just too slow to rely on to monitor things like interfaces going down. We leverage heavily API and mysql queries against LibreNMS DB to monitor sanity of our entire network estate and knowing about core link dying or being hammered by traffic 5 minutes after the fact is not very impressive (people are usually shouting very loudly by then anyway…)
Also traffic stats averaged into 5 minutes buckets are not super useful for granular visibility either, especially with our rather busty network traffic patterns.
So the next ideal option would be to be able to selectively specify polling rate on the device level - we could then set polling to let’s say 2 minutes for those naughty devices which tend to overrun. As far as I am aware, this is currently not possible - please correct me if I am wrong though?
Taking the above into consideration, we simply let some device overrun and use this as ‘poor man’s per-device polling rate’ mechanism. I did not look into what specifically happens in such case (with old service, at least), but this seems to work fine.
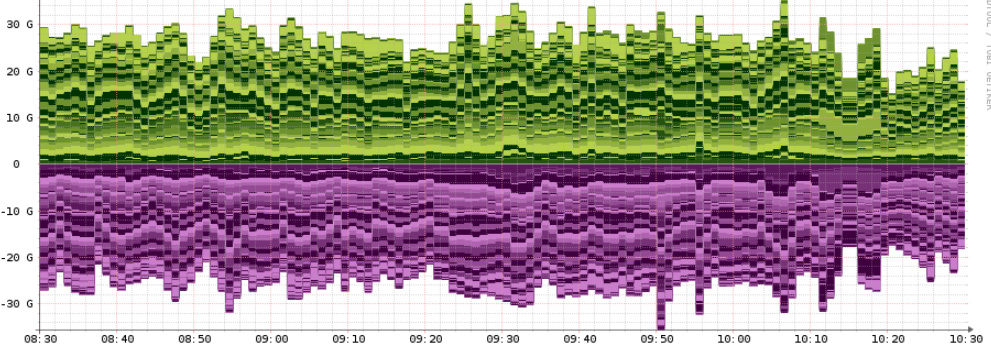
Even for the very busy devices which happen to have frequent > 100 seconds poll time, we are not seeing a problem, for example this is graph for the last 2 hours from the most naughty Nexus device, it does not show any gaps:
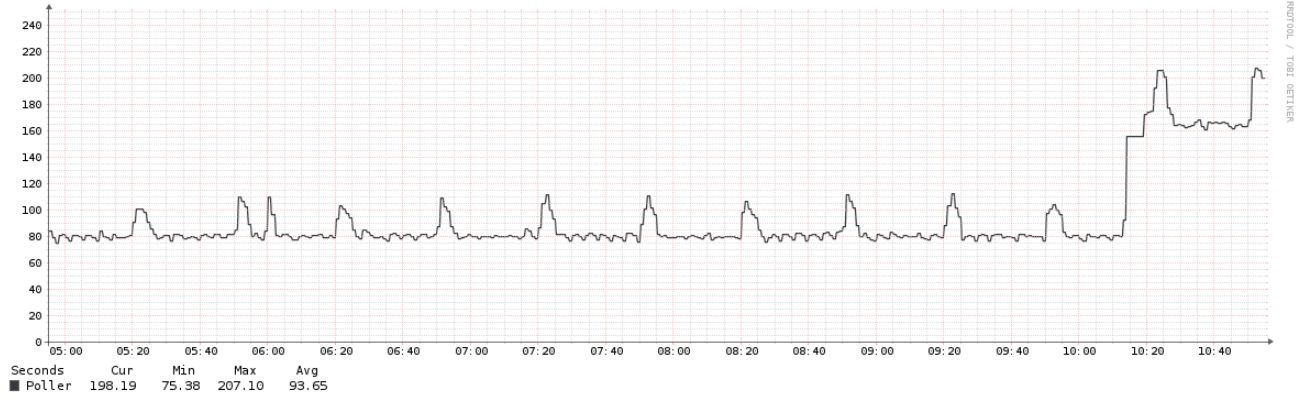
Poller times for this specific guy are as follows:
As you can see there are no gaps in poller stats, even though the process is constantly overruning. We also get valid ports state, etc information from these overrunning devices. We do very rarely see the gaps on individual graphs, but this is not really a problem.
My assumption is that in the traditional poller/service there is some mechanism that would let the previous job to finish before starting new one, even if it takes longer than 60 seconds. This potentially works as a crude ‘dynamic poll interval’ implementation - it is not perfect, but RRD interpolation based on the step time seems to take care of filing in the gaps when the data arrives later or less frequently than expected in those corner cases. It will just to its best to keep graphs accurate as quickly as possible for that specific device.
So I would add another item to your list:
D. Just let polling run for as long as it needs to run (up to a certain threshold of course, like 4x of poll interval value or so) without interfering with it or spawning a new job at the same time - and let RRD tool to fill in the gaps. There will be some accuracy / precision loss in this case or even occasional gaps, but this is acaceptable since we are talking about only 5% or so devices affected by this - and the benefit of 60 second polling for the rest of the estate totally justifies this.
I hope this all makes sense, very sorry if somehow I come across as pushy or ‘assholistic’ about it - I am just very passionate about LibreNMS and really love this platform and want it to be even better than is now when it comes to polling