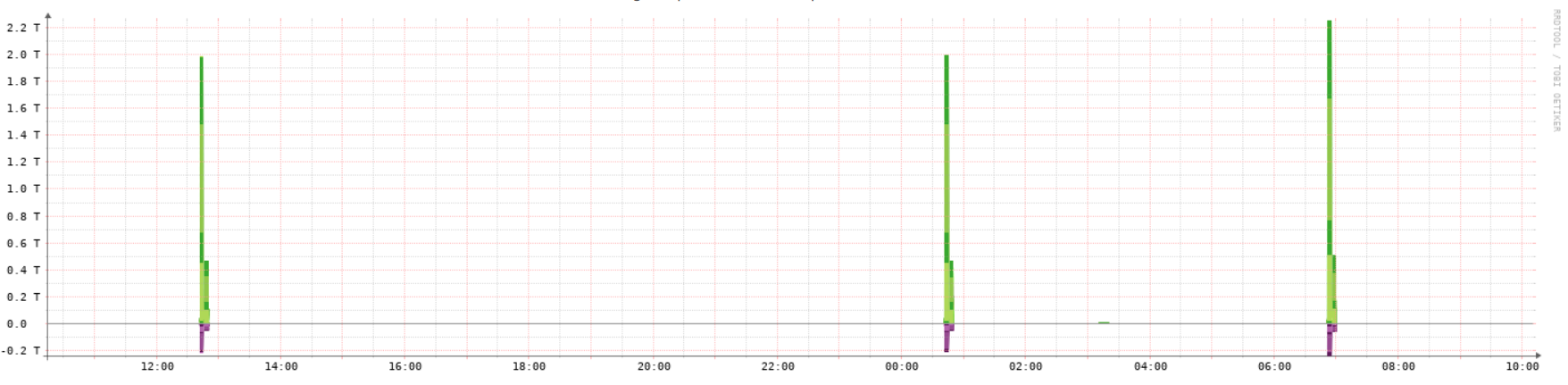
Ok I think I am seeing the same problems as you recently. In the last few days and last night in particular I’ve been seeing some crazy, random high traffic spikes that are triggering traffic alerts across many different switches.
Here are some examples from the wave of alerts I got last night, each one from a different switch of different models in a different part of the network :
High utilisation ports:
#1: Port: Slot0/1
Port Description: Ethernet Interface
Link Rate: 100 Mbit/s
Receive Rate: 108.85 Mbit/s
Transmit Rate: 5,080.27 Mbit/s
High utilisation ports:
#1: Port: eth0
Link Rate: 1,000 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 48,834.04 Mbit/s
High utilisation ports:
#1: Port: 1/1
Port Description: D-Link DGS-3120-48PC R4.00.015 Port 1 on Unit 1
Link Rate: 1,000 Mbit/s
Receive Rate: 1,188.71 Mbit/s
Transmit Rate: 11,465.23 Mbit/s
#2: Port: 1/2
Port Description: D-Link DGS-3120-48PC R4.00.015 Port 2 on Unit 1
Link Rate: 1,000 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 5,447.93 Mbit/s
High utilisation ports:
#1: Port: Slot0/2
Port Description: Ethernet Interface
Link Rate: 100 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 2,346.08 Mbit/s
#1: Port: Slot0/1
Port Description: Ethernet Interface
Link Rate: 100 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 3,483.05 Mbit/s
#2: Port: Slot0/2
Port Description: Ethernet Interface
Link Rate: 1,000 Mbit/s
Receive Rate: 33.96 Mbit/s
Transmit Rate: 6,297.74 Mbit/s
High utilisation ports:
#1: Port: Slot0/2
Port Description: Ethernet Interface
Link Rate: 1,000 Mbit/s
Receive Rate: 22,304.03 Mbit/s
Transmit Rate: 1,874,836.54 Mbit/s
#1: Port: eth1/0/1
Port Description: D-Link Corporation DGS-1250-28XMP HW A1 firmware 2.02.030
Port 1
Link Rate: 1,000 Mbit/s
Receive Rate: 256.65 Mbit/s
Transmit Rate: 3,702.75 Mbit/s
#2: Port: eth1/0/2
Port Description: D-Link Corporation DGS-1250-28XMP HW A1 firmware 2.02.030
Port 2
Link Rate: 1,000 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 5,304.65 Mbit/s
#1: Port: 1/1
Port Description: Ethernet Interface
Link Rate: 1,000 Mbit/s
Receive Rate: 100.11 Mbit/s
Transmit Rate: 1,511.30 Mbit/s
#2: Port: 1/2
Port Description: Ethernet Interface
Link Rate: 1,000 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 966.40 Mbit/s
#1: Port: GigabitEthernet1
Link Rate: 100 Mbit/s
Receive Rate: 38,199.96 Mbit/s
Transmit Rate: 1,672.78 Mbit/s
#2: Port: GigabitEthernet2
Link Rate: 100 Mbit/s
Receive Rate: 37,463.11 Mbit/s
Transmit Rate: 1,295.55 Mbit/s
#1: Port: 1/2
Port Description: D-Link DGS-3120-48PC R4.00.015 Port 2 on Unit 1
Link Rate: 100 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 4,192.39 Mbit/s
#1: Port: Slot0/1
Port Description: Ethernet Interface
Link Rate: 1,000 Mbit/s
Receive Rate: 178.03 Mbit/s
Transmit Rate: 2,077.18 Mbit/s
#2: Port: Slot0/2
Port Description: Ethernet Interface
Link Rate: 1,000 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 4,759.95 Mbit/s
#1: Port: Slot0/1
Port Description: Ethernet Interface
Link Rate: 1,000 Mbit/s
Receive Rate: 2.45 Mbit/s
Transmit Rate: 3,355.53 Mbit/s
#2: Port: Slot0/2
Port Description: Ethernet Interface
Link Rate: 1,000 Mbit/s
Receive Rate: 0.00 Mbit/s
Transmit Rate: 2,988.57 Mbit/s
On the traffic graphs I see spikes at this time going as high as 7Gbps on devices that only have 1Gbps ports… so something really whacky is going on here.
I’m also intermittently seeing sensor devices like temperature sensors turning returning 0 values - setting off low temperature alerts, for example:
Alerting sensors:
Sensor #1: edge
Temperature: 0 °C
Low Temperature Limit: 20 °C
Sensor #2: temp1
Temperature: 0 °C
Low Temperature Limit: 20.875 °C
And also voltage alerts:
Alerting sensors:
Sensor #1: vddgfx
Sensor class: voltage
Current value: 0
Low Limit: 0.74885
This one above is interesting as it’s the ubuntu server that runs LibreNMS! So it’s polling itself over loopback and yet still returning bogus temperature values for both advertised temperature sensors.
Here’s voltage sensors on another linux based server reporting 0 voltage:
Alerting sensors:
Sensor #1: vddgfx
Sensor class: voltage
Current value: 0
Low Limit: 0.74885
Sensor #2: vddnb
Sensor class: voltage
Current value: 0
Low Limit: 0.87635
I wonder if there have been any updates in the last few weeks affecting SNMP polling ? Looking back in my alert logs I seem to have been getting intermittent bogus 0 values for sensors since around the 20th of October, although it seems to have got a lot worse in the last week.
Anyone have any idea why SNMP polling keeps returning bogus 0 values ? While I haven’t checked I’m fairly sure that bogus 0 values for interface traffic counters is what is causing the spikes on the traffic graphs as well.
Is it possible to check specific polled historical data with an SQL query to see what values were being returned when the alerts happened, or is the data just fed into rrdtool to store in it’s own database, and thus resolution is lost over time ?
Edit: I should probably add that most of these alerts occurred soon after 12:17am last night, which would have been soon after an automatic update.